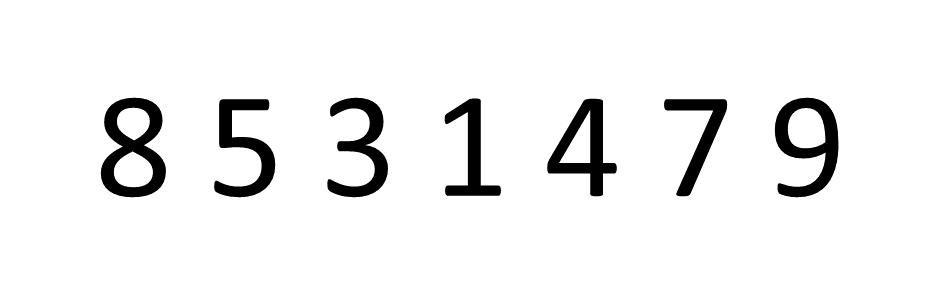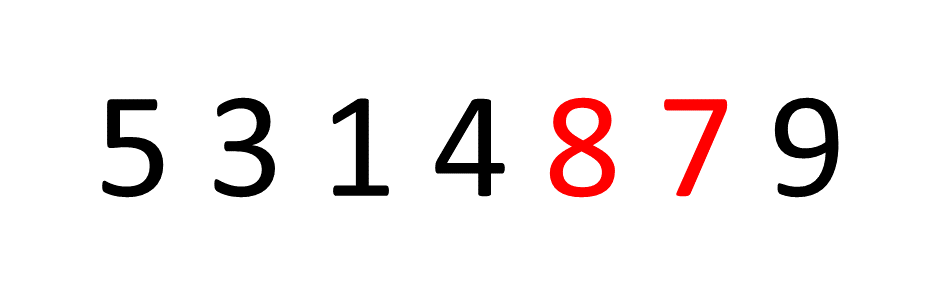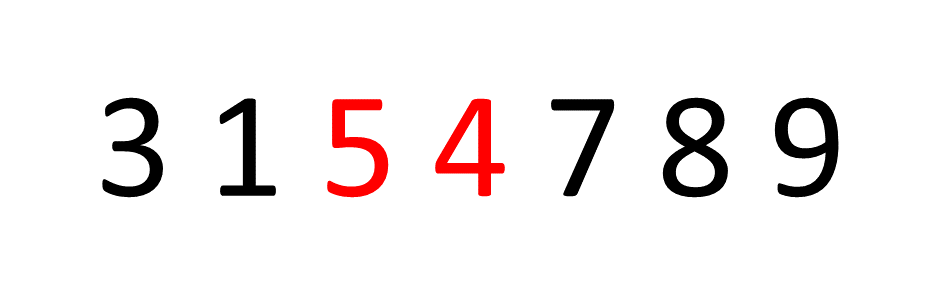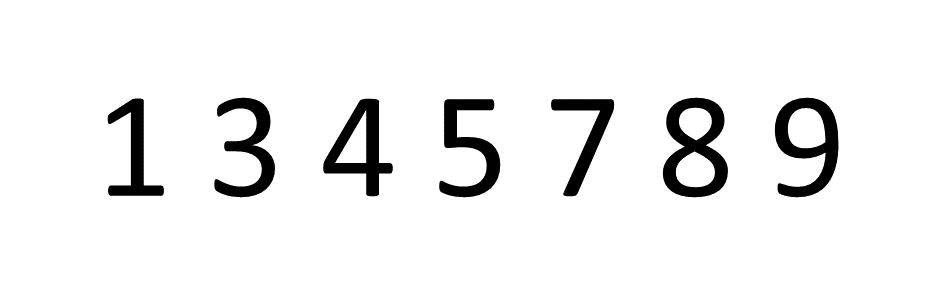时间复杂度(Time complexity) 1.一个例子 情景:在一个有100个学生的教室里,仅有一名学生没过英语四级,我们要找到这名学生
方法一:问每一个学生是否有过四级,时间复杂度为O(n)
方法二:问每一个学生两个问题:1.是否有过四级 2.其他99个人过四级的情况,时间复杂度为O(n2)
方法三:将100人分成两组,然后问没过四级的是在第一组还是在第二组,然后将该小组又分成两部分,再次询问,以此类推,直到最后找到没过四级的那个学生,时间复杂度为O(log n)
如果只有一个学生知道笔隐藏在哪个学生上,我可能需要进行O(n2)搜索。如果一个学生拿着笔,只有他们自己知道,我会使用O(n)。如果所有学生都知道,我会使用O(log n)搜索,但是只会告诉我是否猜对了。
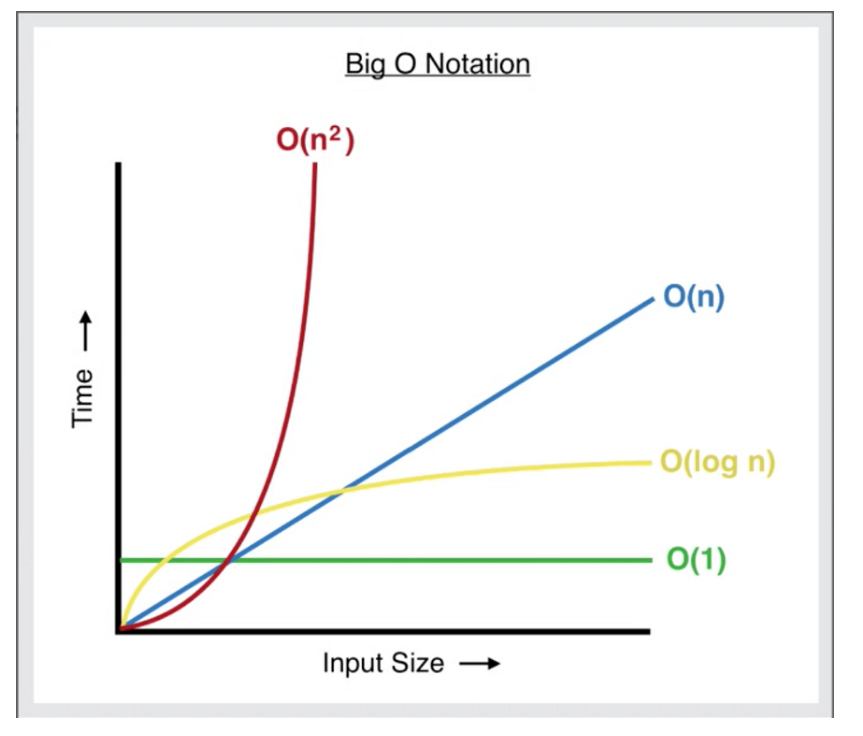
2.时间复杂度的含义 时间复杂度并不等于程序执行时间,我们没有考虑执行代码中每个语句所需的实际时间,而是考虑每个语句执行多少次
3.时间复杂度图示
4.时间复杂度计算方法
将算法/功能分解为单独的操作
计算每个操作的复杂度
将每个操作的复杂度加起来
删除常量
找到最高阶项-这就是我们认为算法/函数的复杂度
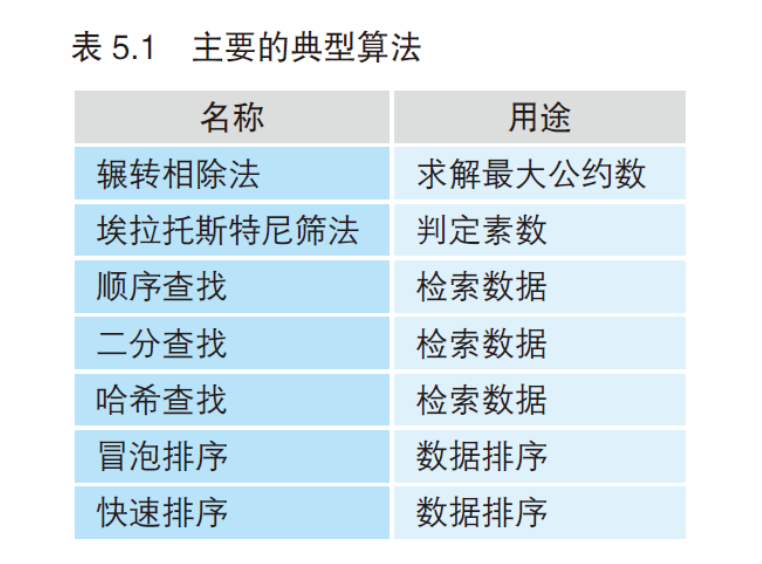
经典算法一览
辗转相除法(Euclidean algorithm) 1.基本概念
辗转相除法又称为欧几里得算法,常用于求解最大公约数
算法原理:若a除以b的余数为r , 则有 gcd(a , b) = gcd( b ,r )
算法思路:大数除于小数得余数,该余数再与小数重复上面步骤,直到最后得小数为0,这时大数即为最大公约数
2.基本案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <stdio.h> int gcd (int a, int b) if (a == 0 ){ return b; } return gcd(b%a, a); } int main () int a = 10 ; int b = 15 ; printf ("GCD(%d, %d)=%d\n" , a, b, gcd(a,b)); a = 35 ; b = 10 ; printf ("GCD(%d, %d)=%d\n" , a, b, gcd(a,b)); a = 31 ; b = 2 ; printf ("GCD(%d, %d)=%d\n" , a, b, gcd(a,b)); }
语法解析:
b%a即b除以a后的余数,当b<a时,返回b,所以在以上程序中,我们不需要比较a,b大小,比如gcd(35,10) ,经过b%a会变成gcd(10,35)递归是一种特殊的循环,其停止的信号是return语句
以上程序的时间复杂度是:O(Log min(a, b))
3.扩展案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <stdio.h> int gcdExtended (int a, int b, int *x, int *y) if (a==0 ){ *x = 0 ; *y = 1 ; return b; } int x1,y1; int gcd = gcdExtended(b%a, a, &x1, &y1); *x = y1 - (b/a) * x1; *y = x1; return gcd; } int main () int x, y; int a = 35 ; int b = 15 ; int g = gcdExtended(a, b, &x, &y); printf ("a*%d + b*%d = %d " , x, y, g); return 0 ; }
语法解析:
以上程序目的是为了计算: ax + by = gcd(a, b) 中的x,y
本程序使用了指针,可以在另一个函数中修改主函数的值,避免变量作用域的问题。在主函数内,可以通过&x,&y将x,y的地址传给其他函数,其他函数定义指针int *x, int *y存储地址,然后再用*x,*y读取地址中存的值即可修改主函数中的变量
int gcd = gcdExtended(b%a, a, &x1, &y1);使程序反复执行其上面的语句,直至a==0,这时可以得到gcd,和x1=0,y1=1的初始值。然后再开始与以上执行方向相反执行其下面的语句。最后return gcd实际上在第二部分的循环中,值不变主函数执行时,gcdExtended中的地址是主函数x,y的地址,而递归函数中的地址是x1,y1的地址;x1,y1存储的是上一个循环中的*x,*y
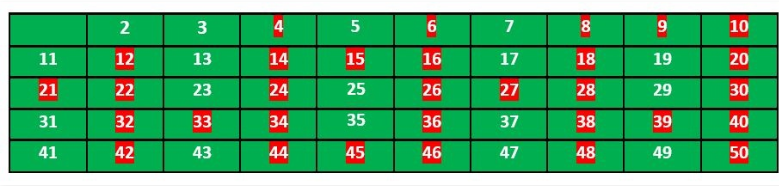
埃拉托斯特尼筛法(sieve of Eratosthenes) 1.基本概念 埃拉托斯特尼筛法是一种常用的素数筛法,可以筛选一定范围自然数内的质数(Prime numbers),时间复杂度:O(n log log n )
埃拉托斯特尼筛法演示动画(摘自维基百科)
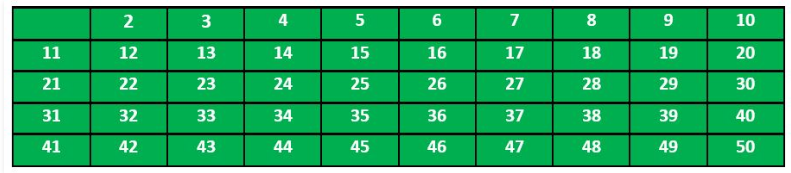
2.实现步骤 该筛法的基本步骤案例,筛选2-50范围内的素数
(1)创建2-50所有数字的列表
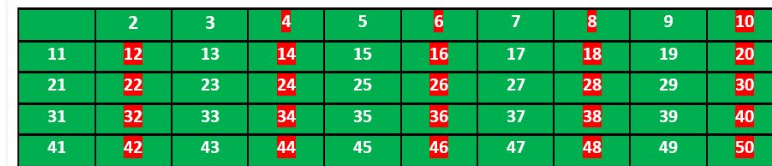
(2)标记所有2的倍数 且大于或等于其平方(即4) 的数字
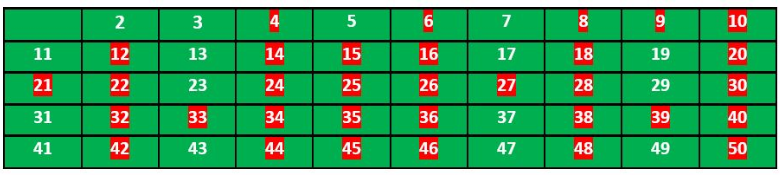
(3)标记所有3的倍数 且大于或等于其平方(即9) 的数字
(4)标记所有5的倍数 且大于或等于其平方(即25) 的数字
(5)标记所有7的倍数 且大于或等于其平方(即49) 的数字
查无数字,则跳过这一步
(6)去掉列表中标记的数字,剩下的未被标记数字即为素数:2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47.
3.基本案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <stdio.h> void SieveOfEratosthenes (int n) bool primes[n+1 ]; for (int i = 2 ; i<=n; i++) { primes[i] = true ; } for (int p=2 ; p*p<=n; p++){ if (primes[p] == true ){ for (int i=p*p; i<=n; i+=p){ primes[i] = false ; } } } for (int p=2 ; p<=n; p++){ if (primes[p]){ printf ("%d\n" ,p); } } } int main () int n; printf ("输入筛选范围:" ); scanf ("%d" ,&n); SieveOfEratosthenes(n); return 0 ; }
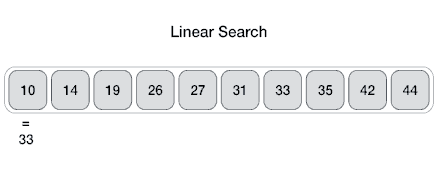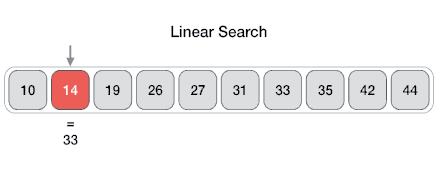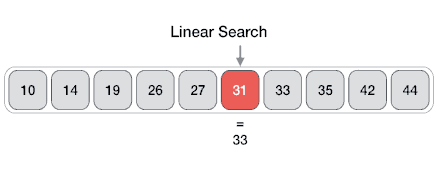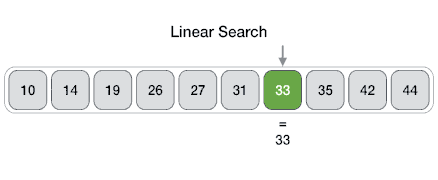
线性查找(Linear search) 1.基本概念 线性查找时间复杂度为:O(n)
线性查找的步骤如下:
从arr []的最左边元素开始,然后将x与arr []的每个元素一一比较
如果x与元素匹配,则返回索引。
如果x与任何元素都不匹配,则返回-1。
线性查找示意图如下:
2.基本案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <stdio.h> int search (int arr[], int n, int x) for (int i=0 ; i<n; i++){ if (arr[i]==x){ return i; } } return -1 ; } int main (void ) int arr[] = {2 , 3 , 5 , 10 , 20 , 40 }; int x = 10 ; int n = sizeof (arr) / sizeof (arr[0 ]); int result = search(arr, n, x); (result==-1 )? printf ("目标不存在" ):printf ("目标所在索引为%d" , result); return 0 ; }
二分查找(Binary Search) 1.基本概念 二分查找的对象是从小到大的数组,其时间复杂度可以写作:O(Log n)
二分查找步骤:
将x与中间元素比较
如果x与中间元素匹配,则返回中间索引
否则如果x大于中间元素则取中间元素后右半边数组重复操作
否则如果x小于中间元素则取中间元素后左半边数组重复操作
二分查找示意图:
2.基本案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 #include <stdio.h> int binarySearch (int arr[], int l, int r, int x) if (r >= l){ int mid = l + (r - l) / 2 ; if (arr[mid] == x){ return mid; } if (arr[mid] > x){ return binarySearch(arr, l, mid-1 , x); } return binarySearch(arr, mid + 1 , r, x); } return -1 ; } int main (void ) int arr[] = {2 , 3 , 5 , 10 , 20 , 40 }; int x = 10 ; int n = sizeof (arr) / sizeof (arr[0 ]); int result = binarySearch(arr, 0 , n - 1 , x); (result==-1 ) ? printf ("目标不存在" ) : printf ("目标所在索引为%d" , result); return 0 ; }
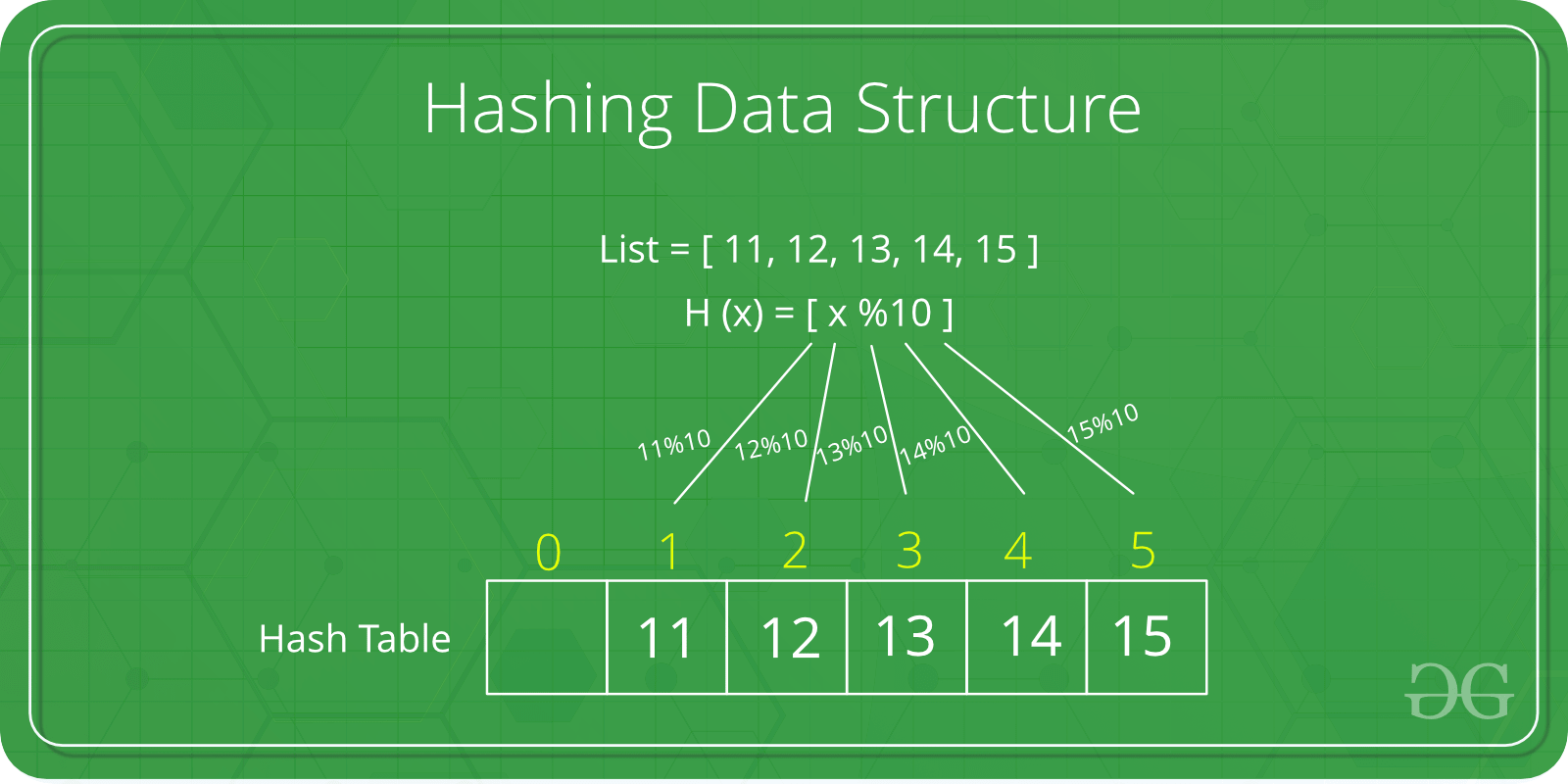
哈希表(Hash table) 1.基本概念 哈希表是一种数据结构 ,其以键值对的形式表示数据。每一个键都映射哈希表中的一个值(与关联数组类似)
在哈希表中,对键进行处理以生成映射到所需元素的新索引。此过程称为hashing。
哈希表是存储和检索元素的有效方法,所以其也是一种有效的查找算法
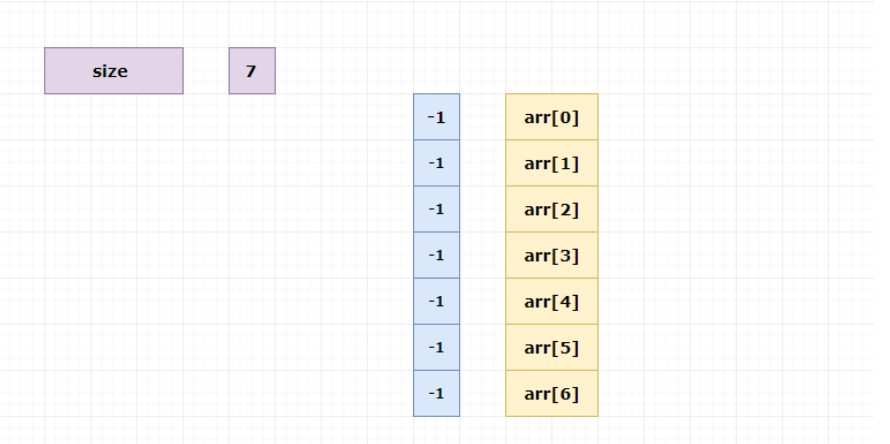
2.实现步骤 (1)哈希表初始化
在将元素插入数组前,将数组默认值设为-1(-1表示元素不存 在或特定的索引可以插入)
(2)插入元素
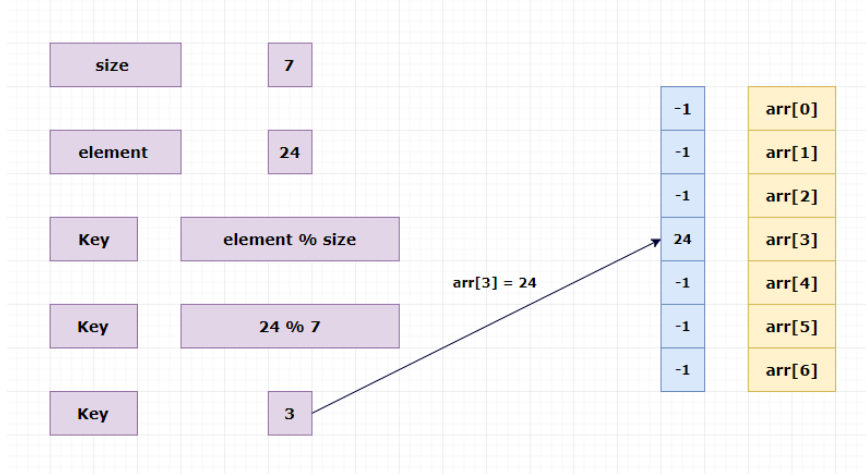
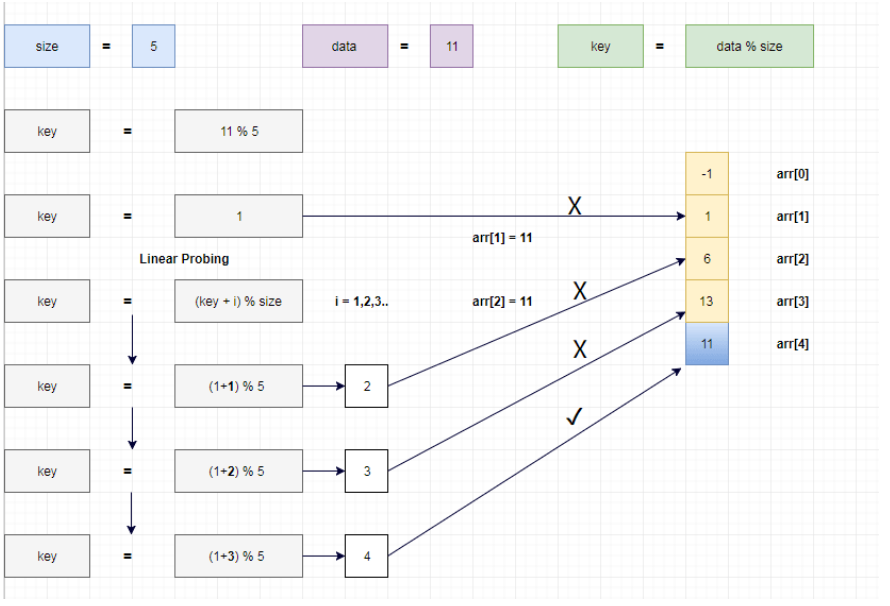
哈希表插入元素的经典算法是:key = element % size (key即数据插入位置,element即元素,size即数组大小)
如插入数字24
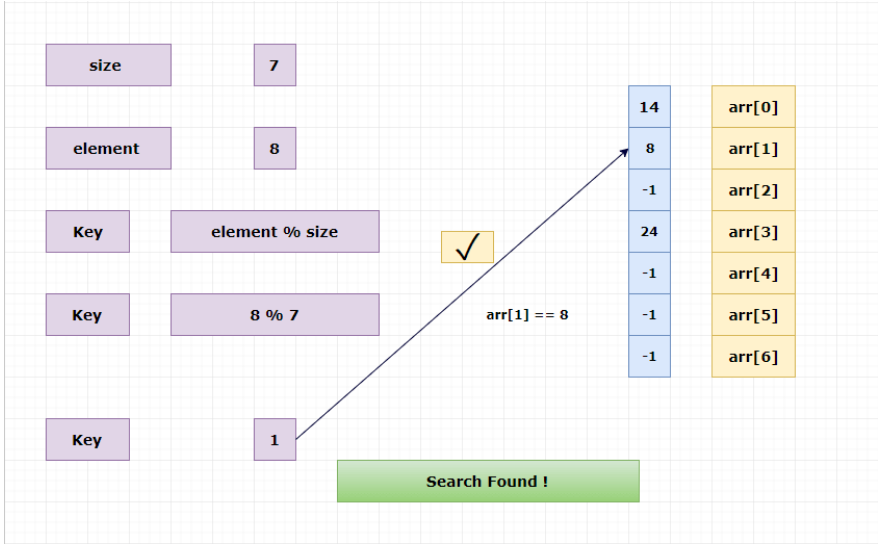
(3)搜索元素
搜索元素和插入元素使用同一算法获得索引(key),再按索引查找对应元素
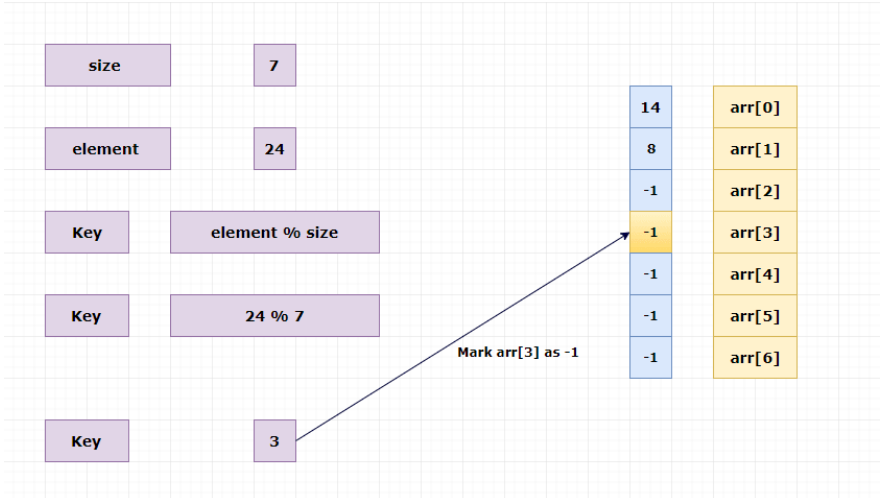
(4)删除元素
在哈希表中删除元素并不是指将数组中的元素移除,而是将元素的值初始化为-1
3.基本案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 # include <stdio.h> # define size 7 int arr[size]; void init () int i; for (i=0 ; i<size; i++){ arr[i] = -1 ; } } void insert (int value) int key = value % size; if (arr[key] == -1 ){ arr[key] = value; printf ("%d 插入到 arr[%d]\n" , value, key); } else { printf ("该位置存在冲突" ); } } void del (int value) int key = value % size; if (arr[key] == value){ arr[key] = -1 ; } else { printf ("该值不存在" ); } } void search (int value) int key = value % size; if (arr[key] == value){ printf ("查有此项" ); } else { printf ("查无此项" ); } } void print () int i; for (i=0 ; i<size; i++){ printf ("arr[%d] = %d\n" , i, arr[i]); } } int main () init(); insert(10 ); insert(4 ); insert(2 ); insert(5 ); printf ("\n" ); print(); printf ("\n" ); del(5 ); print(); printf ("\n" ); search(4 ); }
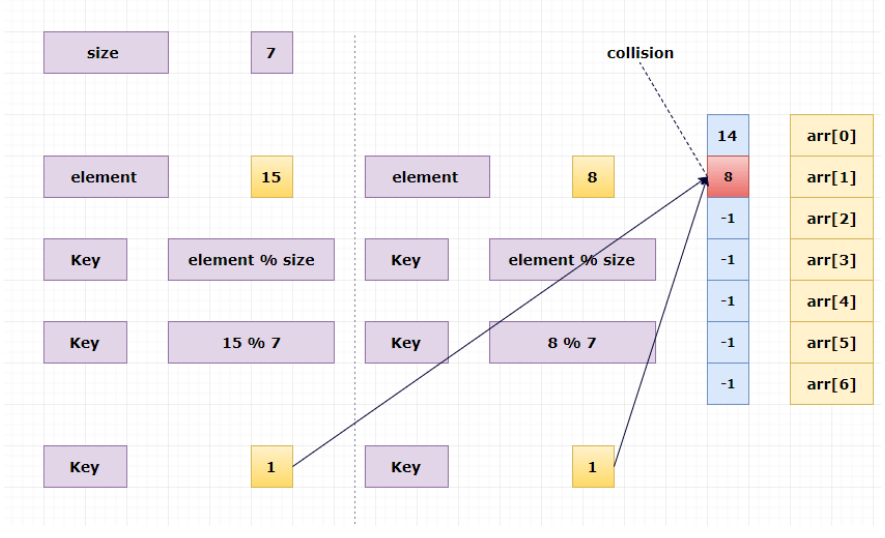
4.哈希冲突(collision) 如果存在插入元素算法得到得索引相同,会出现哈希冲突的情况
以下介绍几种避免哈希冲突的方法
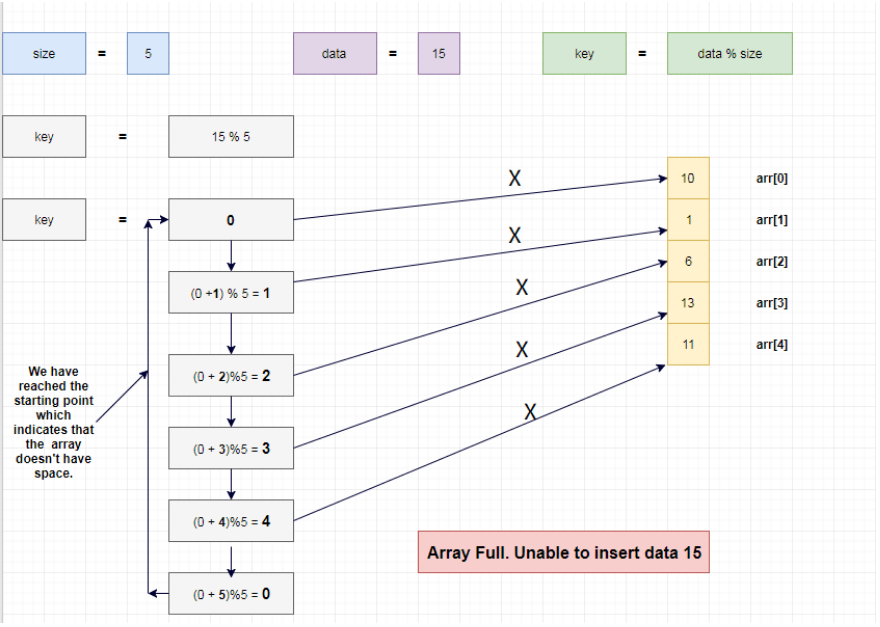
5.线性探测(Linear Probing) (1)方法简介:通过key = element % size计算索引,如果该索引为空则直接填入,如果产生了冲突就检查下一个索引即key = (key+1) % size,重复执行该过程直到找到空间
(2)方法示意图
空间不足的情况:
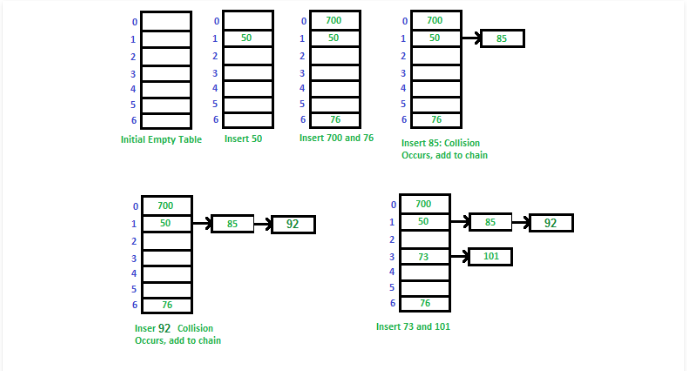
6.单独链表法(separate chaining) (1)方法简介
单独链表法又被称为开放式哈希表(Open hashing),它采用数据结构中的链表(linked list)来解决哈希冲突的问题,这样的哈希表永远也不会被填满
这种方法使哈希表的每个单元指向具有相同索引值的链表
(2)方法示意图
(3)使用案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 # include <stdio.h> # include <stdlib.h> # define size 7 struct node { int data; struct node * next ; }; struct node * chain [size ];void init () int i; for (i=0 ; i<size; i++){ chain[i] = NULL ; } } void insert (int value) struct node *newNode =malloc (sizeof (struct node)); newNode->data = value; newNode->next = NULL ; int key = value % size; if (chain[key] == NULL ){ chain[key] = newNode; } else { struct node *temp = chain[key]; while (temp->next){ temp = temp->next; } temp->next = newNode; } } int search (int value) int key = value % size; struct node *temp = while (temp){ if (temp->data == value){ return 1 ; } return 0 ; } } int del (int value) int key = value % size; struct node *temp = if (temp != NULL ){ if (temp->data == value){ dealloc = temp; temp = temp->next; free (dealloc); return 1 ; } else { while (temp->next){ if (temp->next->data == value){ dealloc = temp->next; temp->next = temp->next->next; free (dealloc); return 1 ; } temp = temp->next; } } } return 0 ; } void print () int i; for (i=0 ; i<size; i++){ struct node *temp = printf ("chain[%d]-->" ,i); while (temp){ printf ("%d-->" , temp->data); temp = temp->next; } printf ("NULL\n" ); } } int main () init(); insert(7 ); insert(0 ); insert(3 ); insert(10 ); insert(4 ); insert(5 ); printf ("\n" ); print(); printf ("\n" ); if (del(10 )){ print(); } else { printf ("删除项不存在" ); } return 0 ; }
冒泡排序(Bubble Sort) 1.基本概念 (1)冒泡排序通过重复交换错误顺序的两个数来工作
(2)冒泡排序步骤:
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
(3)冒泡排序示意图:
2.基本案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <stdio.h> void swap (int *xp, int *yp) int temp = *xp; *xp = *yp; *yp = temp; } void bubbleSort (int arr[], int n) int i, j; for (i=0 ; i<n-1 ; i++){ for (j=0 ; j<n-i-1 ; j++){ if (arr[j]>arr[j+1 ]){ swap(&arr[j], &arr[j+1 ]); } } } } void printAarry (int arr[], int size) int i; for (i=0 ; i<size; i++){ printf ("%d " , arr[i]); } printf ("\n" ); } int main () int arr[] = {64 , 34 , 25 , 12 , 22 , 11 , 90 }; int n = sizeof (arr) / sizeof (arr[0 ]); bubbleSort(arr, n); printf ("排序后的数组:\n" ); printAarry(arr, n); return 0 ; }
快速排序(Quick sort) 参考文章:https://juejin.cn/post/6844904122538278920
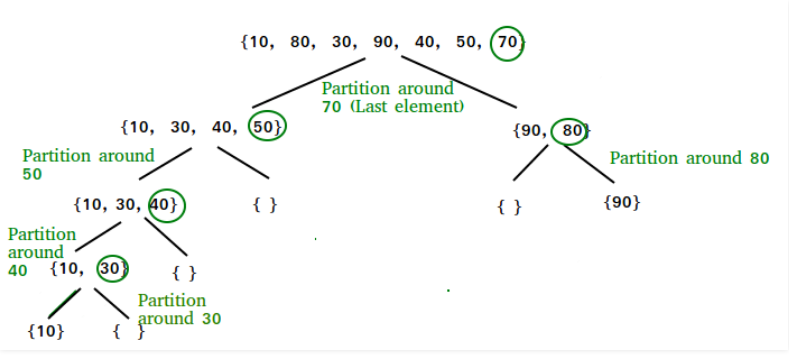
1.基本概念 (1)快速排序是一种分而治之的算法,它会一个元素为枢纽键对数组进行分区,枢纽有以下几种选择,本文以最简单的最后一个元素为枢纽为例
始终选择第一个元素作为枢轴
始终选择最后一个元素作为枢轴
选择一个随机元素作为枢轴。
选择中位数作为枢轴
(2)实现步骤
在给定数组中确定一个元素x作为枢纽
将x放在排序数组中的正确位置
将小于x的元素放在x之前
将大于x的元素放在x之后
去掉枢纽分成两组后重复以上操作
以末尾元素为枢纽排序示意图
(3)将小于x的元素放在x之前,将大于x的元素放在x之后这一步是将一个数组分成两个数组,其运用到了分而治之的思想
将一个数组分成两个数组的方法为:
再从数组的左边找到一个比枢轴元素大的元素,将从上面取元素的位置赋值为该值;
依次进行,直到左右相遇,把枢轴元素赋值到相遇位置。
示意图如下:
2.基本案例 基本案例中也运用了分而治之的方法,当操作步骤与上面步骤相异但是效果相同
选择最后一个元素作为枢纽
从数组左端开始遍历一个数组,先设最左端元素为待交换元素。当遇到比枢纽值小的元素,就将其与待交换元素值相交换,并把下个元素设为待交换元素
完成遍历后,最后交换末尾元素与待交换元素,并返回待交换元素的索引
依据返回的索引将数组分成了两组:左边比枢纽元素小,右边比枢纽元素大
最后再递归分开处理左边数组和右边数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <stdio.h> void quickSort (int [], int , int ) int partition (int [], int , int ) void swap (int *, int *) int main () int n,i; printf ("数组大小\n" ); scanf ("%d" ,&n); int arr[n]; printf ("填入数组数据\n" ); for (i=0 ;i<n;i++) scanf ("%d" ,&arr[i]); quickSort(arr,0 ,n-1 ); printf ("快速排序后的数组\n" ); for (i=0 ;i<n;i++) printf ("%d " ,arr[i]); printf ("\n" ); return 0 ; } void quickSort (int arr[], int start, int end) if (start < end) { int pIndex = partition(arr, start, end); quickSort(arr, start, pIndex-1 ); quickSort(arr, pIndex+1 , end); } } int partition (int arr[], int start, int end) int pIndex = start; int pivot = arr[end]; int i; for (i = start; i < end; i++) { if (arr[i] < pivot) { swap(&arr[i], &arr[pIndex]); pIndex++; } } swap(&arr[end], &arr[pIndex]); return pIndex; } void swap (int *x, int *y) int t = *x; *x = *y; *y = t; }
*y = t;