
汇编基础知识
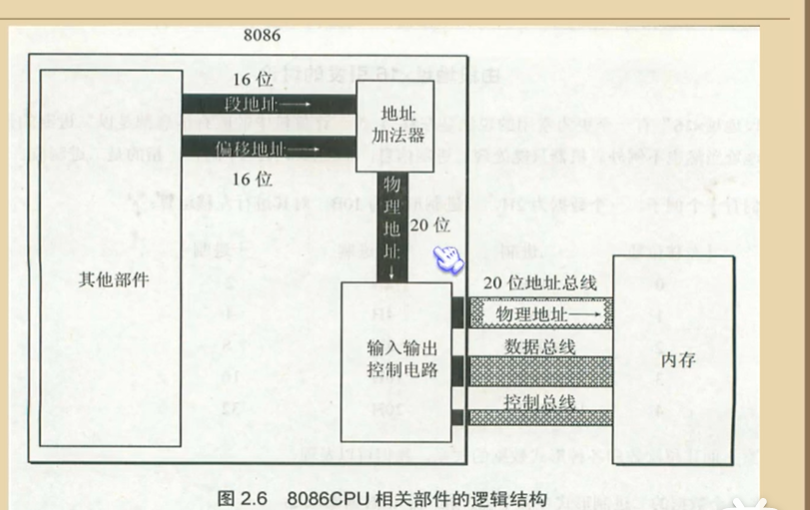
1.CPU对存储器的读写


2.地址总线
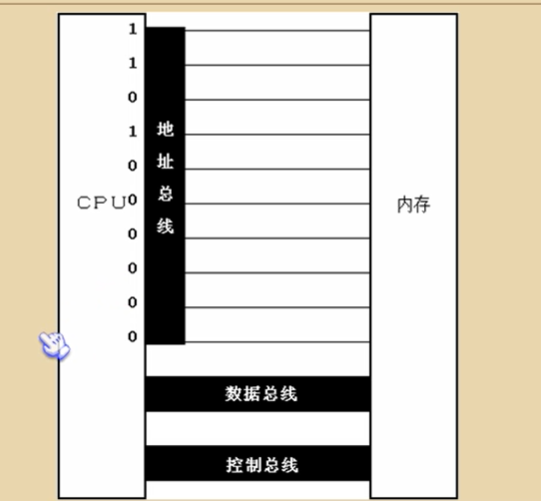
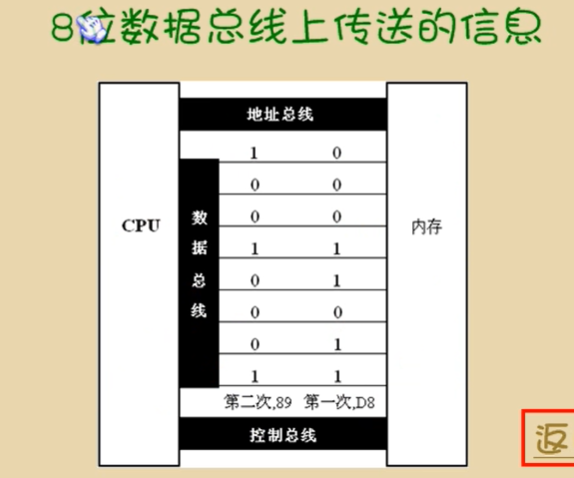
3.数据总线
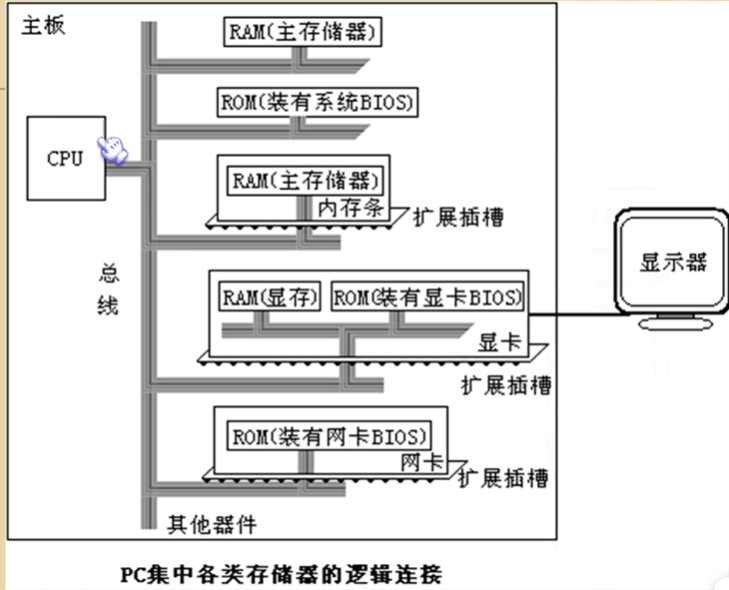
4.PC中各类存储器的逻辑连接
CPU工作原理
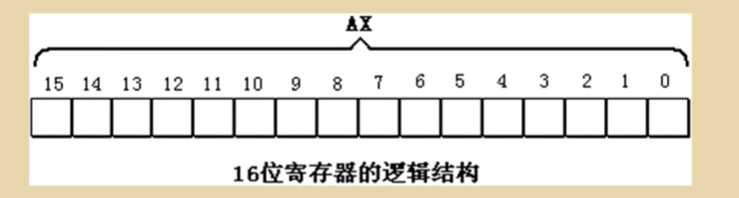
1.寄存器概述

2.通用寄存器



3.基础汇编指令

- 但寄存器超过了4位数(十六进制),只会保留4位的内容
- ax寄存器也可以拆成al,ah两块存储
4.CPU内部逻辑结构


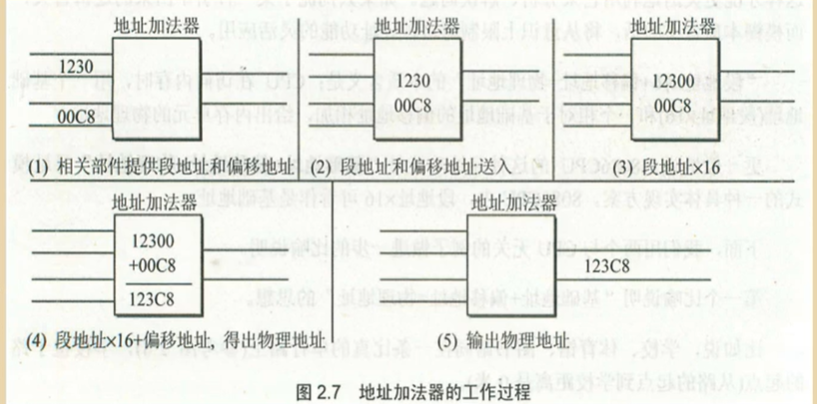
地址加法器工作原理:
5.16位结构的CPU


6.段寄存器

CPU工作流程:
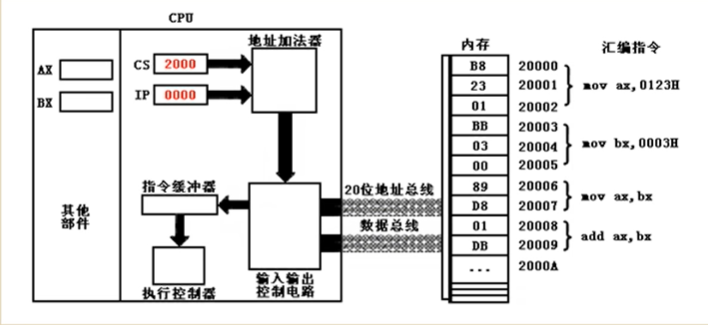

修改CS,IP指令:


7.代码段

内存访问
1.内存中字的存储
CPU中,用16位寄存器来存储一个字。高8位存放高位字节,低8位存放低位字节
字单元:存放一个字型数据(16位)的内存单元,由两个地址连续的内存单元组成

0号是低地址单元,1号是高地址单元
(1)0地址单元中存放的字节型数据是多少? 20H
(2)0地址字单元中存放的字型数据是多少? 4E20H

2.DS寄存器与地址

读取内存单元数据到寄存器中:
1
2
3
4
5
6
7
8
9
10
11
| # 以下三条指令将1000H(1000:0)地址中的数据读到al
# 先将目标地址放入通用寄存器
mov bx, 1000H
# 经过通用寄存器将地址信息传送给ds(8086CPU不支持将数据直接送入段寄存器)
mov ds, bx
# 后面的代码可以自动索引到目标段地址是1000H(ds相当于栈的指针)
# [0]指偏移地址是0,直接读取到1000H的数据(传送8位数据)
mov al,[0]
# 下面这样则是将数据从寄存器送入内存单元(传送16位数据)
mov [0],cx
|

指令
1.mov

1
2
3
4
5
6
7
8
9
10
| # 将数据b放入ax寄存器中
mov ax, b
# ax寄存器中的内容放入bx寄存器中
mov bx, ax
# 内存单元里的内容存入ax寄存器中(内存单元的地址是根据ds + 偏移地址得到)
mov ax, [0]
# ax的内容存入内存单元中
mov [0], ax
# ax中存入的地址传入ds中
mov ds ax
|
2.add与sub
add,sub指令同mov一样,都有两个操作对象

注意add和sub的对象不能有段寄存器
数据段
1.数据段概念

2.读取数据段
(1)读取数据段中前三个单元中的字节数据
1
2
3
4
5
6
7
8
9
| mov ax, 123BH
# 将123BH送入ds,作为数据段的段地址
mov ds, ax
# al存放累加的结果
mov al, 0
# 利用偏移地址读取数据段的单元
add al, [0]
add al, [1]
add al, [2]
|
(2)累加数据段中前三个单元中的字型数据
1
2
3
4
5
6
7
8
9
| mov ax, 123BH
# 将123BH送入ds,作为数据段的段地址
mov ds, ax
# ax存放累加的结果
mov ax, 0
# 利用偏移地址读取数据段的单元
add ax, [0]
add ax, [2]
add ax, [4]
|
注意:一个字型数据占两个单元,所以偏移地址是0,2,4
3.总结


栈
1.CPU提供的栈机制


2.push指令执行过程
先移动指针再放入数据
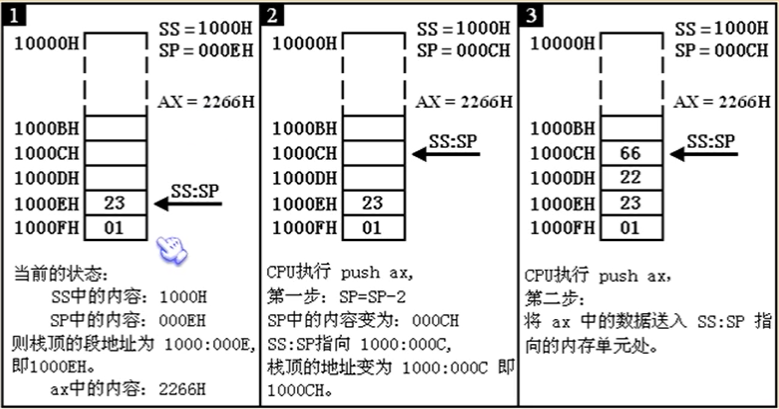
任何时刻ss:sp指向栈顶元素,如果栈的最低部字单元地址位1000:000E,当栈为空时,SP=0100H
3.pop指令执行过程
先弹出数据再移动指针
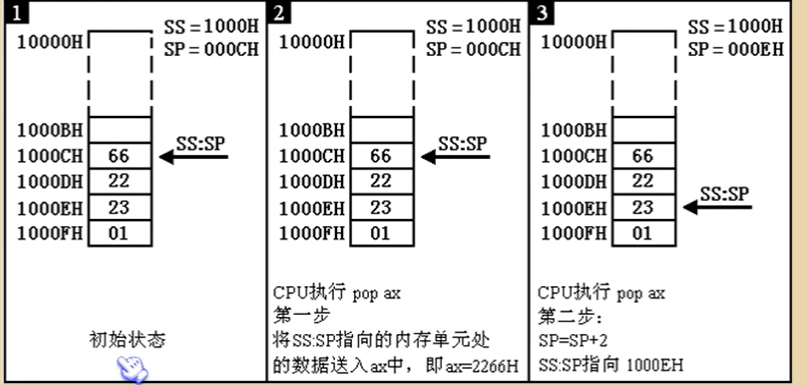
4.栈顶超界问题

5.push和pop指令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # 通用寄存器
# 将寄存器中的数据入栈
push ax
# 用一个寄存器接受出栈的数据
pop bx
# 段寄存器
# 将一个段寄存器中的数据入栈
push ds
# 用一个段寄存器接受出栈数据
pop es
# 内存单元(栈操作都是以字为单位,cpu会从ds中取出段地址加上指令中的偏移地址
# 将一个内存单元的字入栈
push [0]
# 用一个内存字单元接收栈的数据
pop [2]
|
6.栈的实例
将10000H~1000FH这段空间当作栈,初始状态为空,将AX,BX,DS的数据入栈
栈中的空间地址为ss:sp(即ss段地址*10加上sp偏移地址)
1
2
3
4
5
6
7
8
9
10
11
| # 设置栈
# 我们要用ss来定义一个栈,因为ss是段寄存器,所以要使用ax进行中转
# 分析储存空间的地址,sp指向第一个字单元时为000EH,则栈的初始段地址为1000H
mov ax, 1000H
mov ss, ax
# 设置栈顶指针,因为栈为空,所以初始化位置要向下移动一位,sp + 2(向下移动加,向上移动减)
mov sp, 0010H
# 填入数据,sp自动减2
push ax
push bx
push ds
|


栈段
数据段:ds ,代码段:cs, 栈段:ss(这些仅仅是我们编程时的一种安排)

汇编程序
1.指令
1
2
3
4
5
6
7
8
9
10
11
12
13
| assume cs:abc
abc segment
mov ax, 2
add ax, ax
add ax, ax
mov ax, 4c00H
int 21H
abc ends
end
|
2.程序
程序:源代码中最终由计算机执行,处理的指令或数据
程序经编译连接后变成机器码
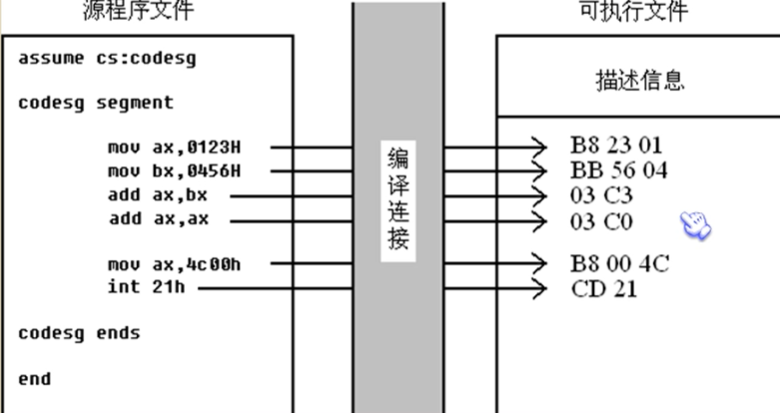
3.标号

4.程序返回
(1)原理
DOS是一个单任务操作系统

(2)实现

(3)总结

5.汇编程序流程图
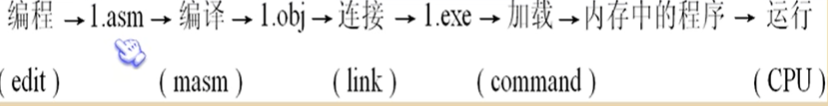
6.程序执行过程的跟踪
(1)exe文件程序加载过程
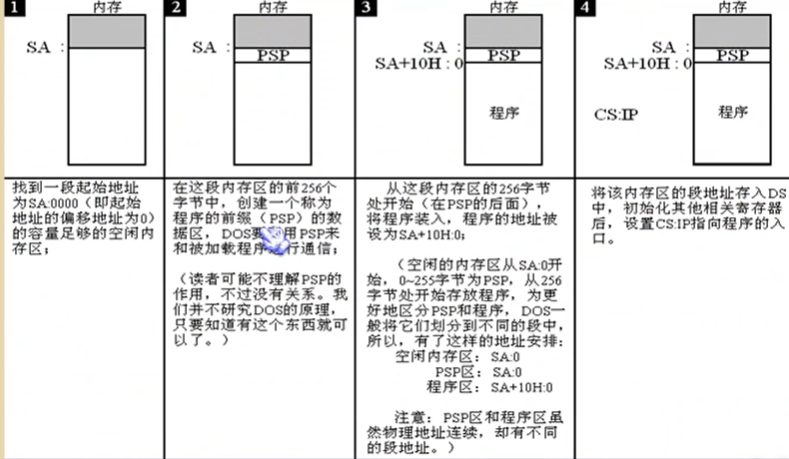
(2)跟踪方法

(3)总结

[BX]和loop指令
1.[bx]
(1)编译器环境下的偏移地址
在debug模式下可以用[0]表示偏移地址,编译器是无法读取[0]的,而是把它当作数值,所以我们需要用[bx]来表示偏移地址

在编译器中无法识别mov ax, [0],但是可以加上段地址从而获得准确地址mov ax, ds:[0]
(2)指令案例


(3)案例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| ; 建立段寄存器寻址,保证编译器可以找到存放代码的段:codesg
assume cs:codesg
; 定义codesg段,里面存放代码
codesg segment
; 定义程序
demo:
; 为ds赋值为2000H
mov ax, 2000H
mov ds, ax
mov bx, 1000H
; 将地址2000:1000处的值赋给ax
mov ax, [bx]
; bx自增1
inc bx
inc bx
; 将ax的值存到2000:1002
mov [bx], ax
inc bx
inc bx
mov [bx], ax
inc bx
; 将ax中的低字节al存入内存单元
mov [bx], al
inc bx
mov [bx], al
; 程序返回
mov ax, 4C00H
int 21H
; 结束段
codesg ends
; 结束程序
end demo;
|
2.loop指令
(1)基础知识


(2)实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| assume cs:code
code segment
mov ax, 2
mov cx, 11
s: add ax, ax
; 跳到地址s处
loop s
mov ax,4C00H
int 21H
code ends
end
|
标号

loop s

(3)循环调试方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| assume cs:code
code segment
; 汇编语言的源程序中数值不能以字母开头,所以要在前面加个0
mov ax, 0ffffH
mov ds, ax
mov bx, 6
mov ax, [bx]
mov dx, 0
mov cx, 3
s: add dx, ax
loop s
mov ax, 4c00H
int 21H
code ends
end
|
1
2
3
4
5
6
7
| ;相关命令
-r ;查看寄存器中所存内容
-u 076c:0 ;读取指定地址块的代码(翻译成汇编指令)
-d 076c:0 ;读取指定地址块的16进制数
-t ;执行一条指令,地址为CS:0000
-g 0014 ;执行到某条指令(地址为cs:0014),可以执行到循环结束后的指令
-p ;直接执行完循环
|
3.loop和[bx]的联合应用
要求:
计算ffff:0 ~ ffff:b 单元中的数据的和,结果存储在dx中
分析:
(1)存储大小分析

(2)存储位置分析


(3)做法总结


(4)程序案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| assume cs:code
code segment
; 设置段地址
mov ax, 0ffffh
mov ds, ax
mov bx, 0
; 设置最终存放寄存器dx
mov dx, 0
; 循环次数的寄存器cx
mov cx, 12
; 循环过程中的al(8位寄存器)充当搬运工
s: mov al [bx]
mov ah, 0
add dx, ax
inc bx
loop s
mov ax, 4c00h
int 21h
code ends
end
|
多段程序
1.在代码段中使用数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| assume cs:code
code segment
; dw定义一段连续的数据
dw 0123H, 0456H, 0789H, 0defh, 0fedh, 0cbah, 0987h
; cpu会从start标记出开始存储代码并执行
start:
mov bx, 0
mov ax, 0
mov cx, 8
s: add ax, cs:[bx]
add bx,2
loop s
mov ax, 4c00h
int 21h
code ends
end start
|
dw定义一段连续的数据
但是cpu会从start标记出开始存储代码并执行
2.在代码段中使用栈
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| ; 利用栈将程序中定义的数据逆序存放
assume cs:code
code segment
; dw定义一个字单元,在cs:0~cs:15中存放
dw 0123h, 0456H, 0789h,0abch, 0defh, 0fedh, 0cbah, 0987h
; dw定义8个字型数据,把这段空间当作栈来使用
dw 0,0,0,0,0,0,0,0
start: mov ax, cs
mov ss, ax
; 栈顶ss:sp 指向 cs:32
mov sp, 32
; 初始化偏移地址,设置循环次数
mov bx, 0
mov cx, 8
; 循环将数据入栈
s: push cs:[bx]
add bx, 2
loop s
mov bx, 0
mov cx, 8
; 循环将数据出栈,顺序变换
s0: pop cs:[bx]
add bx, 2
loop s0
mov ax, 4c00h
int 21h
code ends
end start
|
3.将数据,代码,栈放入不同的段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| ; 分段存储代码,数据,栈
assume cs:code, ds:data, ss:stack
; 数据段存储
data segment
; dw定义一个字单元,在cs:0~cs:15中存放
dw 0123h, 0456H, 0789h,0abch, 0defh, 0fedh, 0cbah, 0987h
data ends
; 栈段存储
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
; 代码段储存
code segment
; 标记start,cpu就会将code段内容当作指令执行
start: mov ax, stack
; 设置ss指向stack,并设置栈顶ss:sp 指向 stack:16
mov ss, ax
mov sp, 16
; ds指向data段
mov ax, data
mov ds, ax
; ds:bx 指向data段第一个单元
mov bx, 0
mov cx, 8
; 循环将数据入栈
s: push cs:[bx]
add bx, 2
loop s
mov bx, 0
mov cx, 8
; 循环将数据出栈,顺序变换
s0: pop cs:[bx]
add bx, 2
loop s0
mov ax, 4c00h
int 21h
code ends
end start
|
4.编写,调试多段程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| ; 分段存储代码,数据,栈
assume cs:code, ds:data, ss:stack
; 数据段存储
data segment
; dw定义一个字单元,在cs:0~cs:15中存放
dw 0123h, 0456H, 0789h,0abch, 0defh, 0fedh, 0cbah, 0987h
data ends
; 栈段存储
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
; 将stack链接到ss,确定了栈段的存储空间
start: mov ax, stack
mov ss, ax
; 找到空间后,因为要存16个字节,所以移动栈指针到栈底
mov sp, 16
; 将data链接到ds,确定了代码段的存储空间
mov ax, data
mov ds, ax
; 栈操作,将数据段的数据压入栈
push ds:[0]
push ds:[2]
; 弹出栈
pop ds:[2]
pop ds:[0]
mov ax, 4c00h
int 21h
code ends
end start
|
- 无论段中要存放多少数据,程序分配的段的空间都是16的倍数(比如我们要在ds中存储2个字,其实际占有空间仍然为16)
- 程序是从上到下为段编排地址,ss,ds,cs只是人为安排的段地址,程序一视同仁地处理
- start可以确定代码段中的指令可以被执行
更灵活的定位内存地址
1.and和or指令
(1)and(与运算,类乘法)应用
使操作对象的相应位设为0
(2)or(或运算,类加法)应用
使操作对象的相应位设为0
2.字符数据
汇编程序中的字符会被编译器转换为相对应的ASCII码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| assume cs:code, ds:data
data segment
; dw定义字型数据(可存16位),db定义字节型数据(可存8位,每个字符对应的ASCII码就是8位的)
db 'unIt'
db 'foRK'
data ends
code segment
start: mov al, 'a'
mov bx, 'b'
mov ax, 4c00h
int 21h
code ends
end start
|
相关规律:
- 大小写字母的转换:小写字母减20H可以转换为其对应的大写字母
- 小写字母的的ASCII大于61H,我们可以通过61H来判断大小写字母
- 一个字母,将第5位置置0,它将变为大写字母(and运算);将第5位置置1,它将变为小写字母(or运算)
3.大小写转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| ; 大小写字母转换
assume cs:code, ds:data
; 存储字符串
data segment
db 'AutoVY'
db 'HelloWorld'
data ends
code segment
start: mov ax, data
mov ds, ax
; 将'AutoVY'全部转为大写
; ds:bx, 指向"AutoVY"第一个字母
mov bx, 0
; 因为AutoVY有6个字母,所以要循环6次
mov cx, 6
; 逐个读取字符
s0: mov al, [bx]
; 将字符与11011111b做与运算,将第5位置0,转换为大写字母
and al, 11011111b
; 将转换后的ASCII码写回原单元
mov [bx], al
; bx自增1,指向下个字母
inc bx
loop s0
; 将'HelloWorld'全部转为小写
; ds:bx, 指向"HelloWorld"第一个字母
mov bx, 6
; 因为HelloWorld有10个字母,所以要循环10次
mov cx, 10
; 逐个读取字符
s1: mov al, [bx]
; 将字符与00100000b做或运算,将第5位置1,转换为小写字母
or al, 11011111b
; 将转换后的ASCII码写回原单元
mov [bx], al
; bx自增1,指向下个字母
inc bx
loop s1
code ends
end start
|
4.[bx+idata]
不改变bx,更加方便获得后续地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| ; 大小写字母转换
assume cs:code, ds:data
; 存储字符串
data segment
db 'AutoVY'
db 'HelloWorld'
data ends
code segment
; 改进程序,以数组的方式处理数据
start: mov ax, data
mov ds, ax
mov bx, 0
mov cx, 5
; 定位第一个字符串字符
s: mov al, [bx]
and al, 11011111b
mov [bx], al
; 定位第二个字符串的字符
mov al, [6+bx]
or al, 00100000b
mov [6+bx], al
inc bx
loop s
code ends
end start
|
5.SI和DI
SI和DI与bx的功能相似,起到了补充bx的作用,常常用于复制数据的场景
我们用ds:si指向要复制的原始数据,用ds:di指向复制的目的空间
优化前:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| ; 利用SI和DI将字符串复制到其后面的数据区
assume cs:code, ds:data
data segment
db 'hello,world'
db '...........'
data ends
code segment
start: mov ax, data
mov ds, ax
; ds:si指向要复制的原始数据,用ds:di指向复制的目的空间
mov si, 0
mov di, 16
mov cx, 8
; 复制
s: mov ax, [si]
; 粘贴
mov [di], ax
; 移动偏移地址
add si, 2
add di, 2
loop s
mov ax, 4c00h
int 21h
code ends
end start
|
优化后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| ; 利用SI和[bx+idata]将字符串复制到其后面的数据区
assume cs:code, ds:data
data segment
db 'hello,world'
db '...........'
data ends
code segment
start: mov ax, data
mov ds, ax
; ds:si指向要复制的原始数据
mov si, 0
mov cx, 8
; 0[si]即[si+0],复制ds:si中的数据
s: mov ax, 0[si]
; 16[si]即[si+16],将数据粘贴到ds:(si+16)
mov 16[si], ax
; 移动偏移地址
add si, 2
loop s
mov ax, 4c00h
int 21h
code ends
end start
|
6.[bx+si]和[bx+di]
[bx+si]的偏移地址为(bx)+(si),也可以写成[bx][si]
[bx+si+idata]的偏移地址为(bx)+(si)+(idata),也可以写成idata[bx][si]
寻址方式应用
1.[bx+si]应用
双重循环需要共用一个CX,造成在内层的时候覆盖了外层循环的循环计数值
所以我们应该每次开始内层循环时,将外层循环的cx数值保存起来,在执行外层loop前,再恢复
- 当循环内,bx寄存器未被使用,我们可以用bx寄存器临时储存外层循环的cx
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| ; 将数据段中每个单词都改写成大写字母
assume cs:code, ds:data
; 共有四行数据,且每一行占了16个字节
data segment
db 'ibm '
db 'dec '
db 'vim '
db 'dos '
data ends
; 利用[bx+si]双重循环访问数据(类似于二维数组)
code segment
start: mov ax, data
mov ds, ax
; bx定位行
mov bx, 0
mov cx, 4
; 用dx临时存放外层循环的值
s0: mov dx, cx
; si定位列
mov si, 0
; 覆盖cx的值
mov cx, 3
s: mov al, [bx+si]
and al, 11011111b
mov al, [bx+si], al
inc si
loop s
add bx, 16
; 在进行外层循环前恢复外层循环的cx值
mov cx, dx
loop s0
mov ax, 4c00h
int 21h
code ends
end start
|
- cpu的寄存器数量有限容易撞车,我们也可以将暂存的数据放入内容单元中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| ; 将数据段中每个单词都改写成大写字母
assume cs:code, ds:data
; 共有四行数据,且每一行占了16个字节
data segment
db 'ibm '
db 'dec '
db 'vim '
db 'dos '
; 定义一个字用来保存cx
dw 0
data ends
; 利用[bx+si]双重循环访问数据(类似于二维数组)
code segment
start: mov ax, data
mov ds, ax
; bx定位行
mov bx, 0
mov cx, 4
; 将外层循环的cx值保存在data:40H的单元中
s0: mov ds:[40H], cx
; si定位列
mov si, 0
; 覆盖cx的值
mov cx, 3
s: mov al, [bx+si]
and al, 11011111b
mov al, [bx+si], al
inc si
loop s
add bx, 16
; 在进行外层循环前从内存单元中恢复外层循环的cx值
mov cx, dx
loop s0
mov ax, 4c00h
int 21h
code ends
end start
|
数据处理
1.寻址寄存器
- 在8086CPU中,只有bx,bp,si,di这四个寄存器可以用于内存单元的寻找
- bx,bp,si,di这四个寄存器可以单个出现,或只能以以下四种组合出现:bx和si,bx和di,bp和si,bp和di
- bp寄存器,当指令没有显性给出段地址,段地址默认为ss
2.数据位置
(1)数据位置可以在三个位置:cpu内部,内存,端口
(2)数据位置的表达
- 立即数(idata): 如
mov ax, 1,执行前在cpu的指令缓存器中
- 寄存器:如:
mov ax, bx执行,数据在寄存器中
- 段地址(SA)和偏移地址(EA):指令要处理的数据在内存中
3.寻址方式
- 直接寻址:[idata]
- 寄存器间接寻址:[bx]
- 寄存器相对寻址:
[bx].idata(用于结构体);idata[si](用于数组);[bx][idata](用于二维数组)
- 基址变址寻址:
[bx][si](用于二维数组)
- 相对基址变址寻址:
idata[bx][si](用于二维数组)
常用方式(对比C语言):我们可以用[bx+idata+si]的方式来访问结构体,bx对应整个结构体,idata对应结构体中的某一个数据项,用si定位数据项中的每一个元素
c语言:dec.cp[i] => 汇编:bx.10h[si]
4.数据长度
- 通过寄存器指明要处理的数据尺寸,例如:
mov ax,1,ax申请了16位的长度
- 通过操作符
x ptr指明内存单元长度,如word ptr,byte ptr,常用于没有寄存器时访问内存单元
- 指令默认访问数据大小,如
push[1000H],默认处理字单元
5.div指令
(1)基本原则

除数(当除数为8位时,当除数为16位时):

(2)解析
1
2
3
4
5
6
7
8
9
10
11
| ; (al)=(ax)/((ds)*16+0)的商
; (ah)=(ax)/((ds)*16+0)的余数
div byte ptr ds[0]
; (ax)=[(dx)*10000H+(ax)]/((es)*16+0)的商
; (dx)=[(dx)*10000H+(ax)]/((es)*16+0)的余数
div word ptr es:[0]
; (al)=(ax)/((ds)*16+(bx)+(si)+8)的商
; (al)=(ax)/((ds)*16+(bx)+(si)+8)的余数
div byte ptr [bx+si+8]
|
(3) 案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| ; 计算100001/100
assume cs:code
code segment
start:
; 被除数100001转换为十六进制为186A1H,超过了16位(ax存不下)
; 所以我们用dx存储16位溢出的1
mov dx, 1
; ax储存16位数据
mov ax, 86A1H
; 除数100,转换成十六进制为64,虽然8位可以存放
; 但是按照被除数为32位,除数为16位的规则,我们只能用一整个bx存储
mov bx,100
; div指令会自动读取被除数(dx)*10000H+(ax)
; 除以bx
div bx
; 程序返回
mov ax, 4c00h
int 21h
code ends
end start
|
6.伪指令dd
前面我们用db定义字节型数据(8位),dw定义字型数据(16位)
我们用dd定义dword(dobule word 双字,32位)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| ; div计算data段中第一个数据除以第二个数据的商放在第三个数据的储存单元中
assume cs:code,ds:data
; 定义数据段
data segment
; 被除数,dword类型(32位),需要用dx和ax存储
dd 100001
; 除数
dw 100
; 商
dw 0
data ends
code segment
start: mov ax, data
mov ds, ax
; 将ds:0(即第一个数据的低16位)中的数据存入ax中
mov ax, ds:[0]
; 将ds:2(即第一个数据的高16位)中的数据存入dx中
mov dx, ds:[2]
; 用dx:ax中的32位数据除以ds:4(即第二个数据,16位)中的字型数据
div word ptr ds:[4]
; 将商存储在ds:6中
mov ds:[6],ax
; 程序返回
mov ax, 4c00h
int 21h
code ends
end start
|
7.dup
dup是一个操作符
dup会与db,dw,dd等数据定义的伪指令配合使用,用来进行数据的重复
使用案例:db 3 dup(0)定义了三个字节,且值都为0,相当于db 0,0,0
转移指令原理
8086CPU的转移指令有以下几类
无条件转移指令(jmp)
条件转移指令
循环指令(loop)
过程(相当于高级语言的函数)
中断
1.操作offset
offset为伪指令,offset取得标号的偏移地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| assume cs:code
; 将s的一条指令复制到s0
; ---------------------------
code segment
; 复制对象
;-------------------------
s: mov ax, bx
; 获得s指令的偏移地址存在si中
mov si, offset s
; 获得s0指令的偏移地址存在di中
mov di, offset s0
; 从cs:[si]中复制出指令内容
mov ax, cs:[si]
; 粘贴给cs:[di]
mov cs:[di], ax
; 粘贴对象
;----------------------
; nop是空指令,一个可占一个字节(因为要复制的指令是两字节的,所以这里要两个nop)
s0: nop
nop
code ends
end s
|
2.jmp指令
jmp可以无条件转移,可以只修改IP,也可以同时修改CS和IP
jmp指令参数:
1
2
3
4
5
6
7
8
9
10
11
12
| assume cs:code
code segment
start: mov ax, 0
; jmp转移到标记s处
jmp short s
add ax, 1
add ax, ax
s:inc ax
code ends
end start
|
(1)jmp short 标号
- 功能为(IP)= (IP) + 8位位移
- 8位位移= 标号处地址 - jmp指令后第一个字节地址
- short表示位移为8位位移
- 8位位移的范围位-128~127
(2)jmp near ptr 标号
- (IP) = (IP) + 16
- 16位位移= 标号处地址 - jmp指令后第一个字节地址
- 段内近转移
(3)jmp far ptr 标号
(4)jmp 16位寄存器
(5)jmp word ptr 内存单元地址
(6)jmp dword ptr 内存单元地址
3.jcxz指令
有条件跳转指令,所有有条件跳转指令都是短转移,在对应的机器码中包含转移的位移,而不是目的地址
(1)jcxz指令操作
- 当(cx) = 0 时, (IP)= (IP) + 8位位移
- 当(cx)!= 0 时,程序向下执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| ; 在内存2000H段查找第一个值为0的字节,找到后将其偏移地址存储在dx中
assume cs:code
code segment
start: mov ax, 2000H
mov ds, ax
mov bx,0
; 循环查找内存
; ----------------------------
; cx存放16位(字),但是要求按8位(字节)处理,所以要分高低位分别存储
s: mov ch, 0
mov cl, [bx]
; jcxz 放在cx寄存器后,一旦cx=0,即跳转到ok段
jcxz ok
; 不符合条件,bx自增找到下一个单元,利用jmp形成循环
inc bx
jmp short s
; 查找到后运行
; ------------------
ok: mov dx, bx
mov ax,4c00h
int 21h
code ends
end start
|
4.loop指令
loop指令也是有条件跳转指令
loop指令操作
- (cx) = (cx) - 1
- 当(cx) != 0 ,(IP)= (IP) + 8位位移
- 当(cx) = 0 时,程序向下运行
函数相关指令
call,ret指令都是转移指令,他们都同时修改IP或同时修改CS和IP
1.ret和retf
(1)ret指令
ret指令使用栈中的数据,修改IP内容,实现近转移
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| assume cs:code
; 申请栈的空间
stack segment
db 16 dup (0)
stack ends
code segment
mov ax, 4c00h
int 21h
start:
; 定位栈段位置
mov ax, stack
mov ss, ax
; 确定栈顶指针
mov sp, 16
mov ax, 0
; 将ax值放入供ret使用
push ax
; 这一句好像没什么用
mov bx, 0
; 利用栈中的数据,IP修改为0
ret
code ends
end start
|
(2)retf指令
retf指令用栈中的数据,修改CS和IP的内容,从而实现远转移
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| assume cs:code
stack segment
db 16 dup (0)
stack ends
code segment
mov ax, 4c00h
int 21h
start:
mov ax, stack
mov ss, ax
mov sp,16
mov ax, 0
; 这里的栈需要cs,和IP两个参数
push cs
push ax
mov bx, 0
; 利用栈中的值取出cs:ip并跳转
retf
code ends
end start
|
2.call指令
call指令操作
3.call和ret的配合使用
类似于函数,call调用子程序,执行完后通过ret返回到主程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| assume cs:code
code segment
start:
mov ax, 1
; 确定循环次数
mov cx, 3
; 这里的call完成了两个操作
; 将下一个指令的IP压入栈中
; 跳转到s标记处
call s
mov bx, ax
mov ax, 4c00h
int 21
; 循环3次相加ax
s: add ax, ax
loop s
; 循环结束后,从栈中读到IP,然后跳转会mov bx, ax 句
ret
code ends
end start
|
4.mul指令
mul相乘的两个数,要么是8位的,要么都是16位
- 8位:处理对象放在AL中和8位寄存器或内存字节单元中,结果在AX中
- 16位:处理对象放在AX中和16位寄存器或内存字单元中,结果DX(高位),AX(低位)
1
2
3
4
5
6
7
8
9
10
11
12
13
| ; 乘法使用案例,计算100*10000
; 因为乘数中的10000大于了255,所以必须做16位乘法
assume cs:code
code segment
start:
mov ax, 100
mov bx, 10000
; mul会自动读取ax中的值作为其中一个乘数
mul bx
code ends
end start
|
4.批量数据的传递
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| ; 利用子程序将data段中的字符串转换为大写
assume cs:code
; 利用内存空间传递批量数据作为参数
data segment
db 'TestText'
data ends
code segment
start:
mov ax, data
; ds:si指向字符串(批量数据)所在空间的首地址
mov ds, ax
mov si, 0
; 字符串长度决定循环次数
mov cx, 8
call change
mov ax, 4c00h
int 21h
change:
and byte ptr [si], 11011111b
inc si
loop change
ret
code ends
end start
|
上面这个利用了内存批量传参,使用栈也可以达到同样效果
5.解决除法溢出问题

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| ; 解决除法溢出问题,F4240H/0AH
assume cs:code, ss:stack
code segment
start:
mov ax, stack
mov ss, ax
mov sp, 10h
; 被除数低16位
mov ax, 4240h
; 被除数高16位
mov dx, 0fh
; 除数
mov cx, 0ah
call divdw
mov ax, 4c00h
int 21h
divdw: ; 子程序定义开始
; 低16位入栈保存
push ax
; 高16位放到ax中进行处理
mov ax, dx
; dx置零
mov dx, 0
; H/N,用高位除以除数
div cx
; ax,bx的值为H/N的商,这时候dx的值为H/N的余数
mov bx, ax
; 从栈中恢复低16位
pop ax
; L/N,dx默认为被除数的高16位,ax为低16位
div cx
; 将余数放到cx中
mov cx, dx
; 将结果高16位放到dx中,结果的低16位在ax中
mov dx, bx
; 子程序结束
ret
|
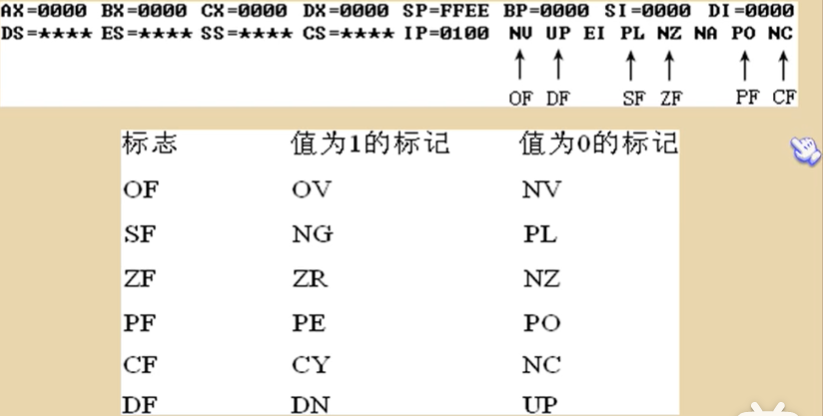
标志寄存器
flag寄存器按位起作用,每一位都有专门的含义

在debug中查看标志寄存器
1.ZF标志
ZF为零标志位,记录相关指令执行后的计算结果是否为0
2.PF标志
PF为奇偶标志位,记录指令执行后,结果的二进制位中1的个数
3.SF标志
SF为符号标志位,记录相关指令执行后的的结果
当CPU在执行add等指令时,实际上就包括了了两层含义(当作有符号处理/当作无符号处理)
4.CF标志
CF为进位标志位,针对无符号数,记录运算的进位值,也记录借位
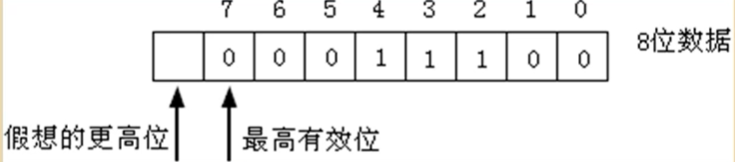
5.OF标志
OF为溢出标志位,针对有符号数
- 结果溢出则为1
- 结果不溢出则为0
- 在进行有符号数的运算时发生了溢出,那么运算的结果是不正确的
6.adc指令
abc为带进位加法指令,利用CF位上的进位值
abc ax, bx 实现功能:(ax) = (ax) + (bx) + CF
1
2
3
4
| ; adc和add指令相配合可以对更大的数据进行加法运算
; add ax, bx
add al, bl
abc ah, bh
|
7.sbb指令
sbb为带借位减法指令,利用CF上的借位值
sbb ax, bx实现的功能:(ax) = (ax) - (bx) - CF
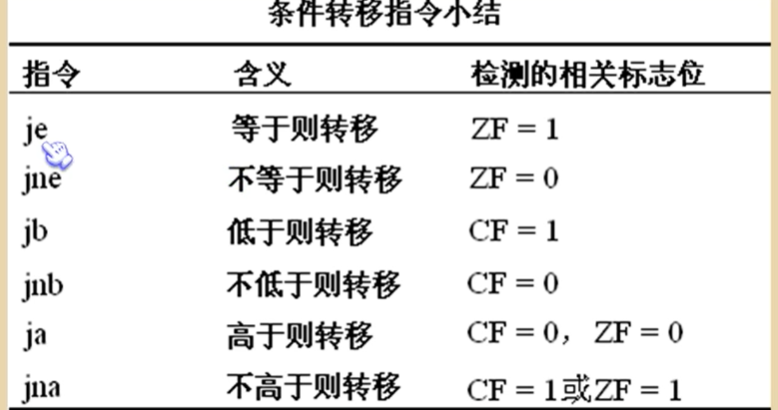
8.cmp指令
cmp指令为比较指令,对标志寄存器产生影响。cmp ax, ax实现的功能:做(ax)-(ax)运算,运算结果不保存,仅对flag的相关位产生影响

9.检测比较结果的条件转移指令

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| ; 比较条件语句(cmp和je配合使用)
; (ah)=(bh)则(ah)=(ah)+(ah),否则(ah)=(ah)+(bh)
assume cs:code
code segment
start:
; cmp 比较ah和bh
cmp ah, bh
; je做相等检测(相当于==),如果符合则跳转到s处
je s
; 无跳转正常向下执行
add ah, bh
; 跳转以绕开符合条件执行的语句
jmp short ok
; 条件符合后执行
s: add ah, ah
; 跳回到第一句,反复循环
ok: ret
code ends
end start
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| ; 统计data段中数值为8的字节的个数,用ax保存统计结果
assume ds:data, cs:code
data segment
db 8,11,8,1,8,5,63,38
data ends
code segment
start:
mov ax, data
mov ds, ax
; ds:bx指向数据段第一个字节
mov bx, 0
; 初始化累加器
mov ax, 0
; 由多少个数据决定循环次数
mov cx, 8
s: ; 和8进行比较
cmp byte ptr [bx], 8
; 不相等直接到下一个循环
jne next
; 相等ax计数
inc ax
next:
; 移动地址,并进行下一次的比较
inc bx
loop s
mov ax, 4c00h
int 21
code ends
end start
|
10.DF标志和串传送指令
DF为方向标志位
DF为0,每次操作后si,di递增
DF为1,每次操作后si,di递减
(1)movsb
以字节为单位传送,将ds:si指向的内存单元中的字节送入es:di中,然后根据标志寄存器DF位的值,将si和di递增或递减
(2)movsw
以字为单位传送,将ds:si指向的内存单元中的字送入es:di中,然后根据标志寄存器DF位的值,将si和di递增或递减2
(3)rep movsb
rep根据cx的值,重复执行后面的串传送指令
(4)DF设置指令
cld指令:将DF置0
std指令:将DF置1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| ; 利用串传输指令,将data段中的第一个字符复制到它后面的空间
assume cs:code
data segment
db 'Welcome to masm!'
db 16 dup (0)
data ends
code segment
start:
mov ax, data
mov ds, ax
; 设置ds:si指向data:0,读取位置
mov si, 0
mov es, ax
; 设置es:di指向data:16,存储位置
mov di, 16
; 设置rep循环16次(总共有16个字符,一个字符一字节)
mov cx, 16
; 设置DF=0,正向传送
cld
; 以字节为单位传送,将ds:si指向的内存单元中的字节送入es:di中
; 并且si,di自增1
rep movsb
mov ax, 4c00h
int 21h
code ends
end start
|
11.pushf和popf
pushf:将标志寄存器的值压栈
popf:从栈中弹出数据,送入标志寄存器中
内中断
1.中断基础知识
中断分类:
外部中断,内部中断,软件中断
中断向量表:
存放着256个中断源所对应的中断处理程序的入口
中断过程:
- 获得中断类型码N
- 标志寄存器的值入栈(保护标志位):pushf
- 设置标志寄存器的TF和IF位为0 :TF=0,IF=0
- CS内容入栈:push CS
- IP内容入栈: push IP
- 从内存地址为中断类型码4和中断类型码\4+2的两个字单元中读取中断程序入口地址设置IP和CS:(IP)=(N*4),(CS)=(N*4+2)
2.中断处理程序
处理步骤:
- 保存用到的寄存器
- 处理中断
- 恢复用到的寄存器
- 用iret指令返回(恢复保存起来的IP,CS和标志位寄存器)
当发生除法溢出时,默认产生0号中断信息,从而引发中断过程

修改默认的中断,令中断表的0号指向200:0处,中断程序就变为了200:0处存储的代码
1
2
3
4
| mov ax, 0
mov es, ax
mov word ptr es:[0*4], 200h
mov word ptr es:[0*4+2], 0
|
3.单步中断
单步中断的中断类型码为1,则它引发的中断过程如下:
- 取得中断类型码1
- 标志寄存器入栈,TF,IF设置为0
- CS,IP入栈
- (IP)=(1*4),(CS)=(1*4+2)
debug使用T命令时,将TF设置为1,引发单步中断
int中断
CPU执行int n 指令,相当于调用一个n号中断的中断过程
1.基本案例
(1)安装程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| ; 安装中断7ch的中断例程
assume cs:code
code segment
start:
; 通过串传送,将程序安装(复制)到安全的内存中(0:200)
; -----------------------------
mov ax,cs
mov ds, ax
; 设置ds:si指向源地址
mov si, offset sqs
mov ax, 0
mov es, ax
; 设置es:di指向目的地址
mov di, 200h
; 计算出传输长度(循环次数)
mov cx, offset sqrend - offset sqr
; 设置传输方向为正
cld
; 传输
rep movsb
; 设置中断向量表
;-----------------------------------
mov ax, 0
mov es, ax
mov word ptr es:[7ch*4], 200h
mov word ptr es:[7ch*4+2], 0
mov ax, 4c00h
int 21h
; 中断后运行的程序(这里是求a的平方)
sqr:
mul ax
; 用iret指令返回(恢复保存起来的IP,CS和标志位寄存器),保证中断结束后继续执行原来的主程序
iret
; 设置一个空指令,方便计算上面程序的长度
sqrend:
nop
code ends
end start
|
(2)调用程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| ; 调用中断例程,求2*3256^2
assume cs:code
code segment
start:
mov ax, 3456
; 调用中断7ch的中断例程,计算出ax数据的平方
int 7ch
; 存放结果,结果乘以2
add ax, ax
adc dx, dx
mov ax, 4c00h
int 21h
code ends
end start
|
端口
CPU可以直接读写3个地方的数据:
1.端口的读写
对0-255以内的端口进行读写
1
2
| in al, 20h ;从20h端口读入一个字节
out 20h, al ;从20h端口写入一个字节
|
对255-65535位的端口进行读写,端口号放在dx中
1
2
3
| mov dx, 3f8h
in ax, dx ; 读入一个字
out dx, ax ; 写入一个字
|
2.shl和shr指令
(1)shl左移指令
- 将一个寄存器或内存单元中的数据向左移位
- 将最后移出的一位写入CF中
- 最低位用0补充
- 如果移动的位数大于1,必须将移动位数放在cl中:
shl al, cl
- 将X逻辑左移一位,相当于执行:X=X*2
(2)shr右移指令
- 将一个寄存器或内存单元中的数据向右移位
- 将最后移出的一位写入CF中
- 最高位用0补充
- 如果移动的位数大于1,必须将移动位数放在cl中:
shr al, cl
- 将X逻辑左移一位,相当于执行:X=X/2
3.读取RAM芯片数据
(1)CMOS RAM芯片与端口
外中断
CPU通过端口和外部设备进行联系
1.外中断信息
(1)外中断源有两类:
(2)当CPU检测到可屏蔽中断信息时
- 如果IF=1,则CPU在执行完当前指令后响应中断,引发中断过程
- 如果IF=0,则不响应可屏蔽中断
(3)设置IF指令
- sti,用于设置IF=1
- cli,用于设置IF=0
2.键盘处理过程
(1)键盘触发中断原理
- 一般按下一个键时产生的扫描码为通码,松开一个键产生的扫描码为断码(扫描码会送入60H)
- 扫描码长度为一个字节,通码第7位为0,断码第7位为1
- 断码 = 通码 + 80H
- 如果是字符键的扫描码,将该扫描码和其对应的字符码送入键盘缓冲区
(2)键盘输入的处理过程
- 键盘产生扫描码
- 扫描码送入60h端口
- 一旦侦测到60h端口有动静,引发9号中断
- CPU执行int 9 中断例程处理键盘输入
直接定值表
1.描述了单位长度的标号
(1)地址标号
1
2
3
4
5
6
7
| ; a,b这里代表地址
a: db 1, 2, 3, 4
b: dw 0
; a,b的使用,获得偏移地址
mov si, offset a
mov bx, offset b
|
(2)地址+长度标号(数据标号)
1
2
3
4
5
6
7
| ; a描述了地址code:0,并描述了从这个地址开始,以后的内存单元都是字节单元
a db 1, 2, 3, 4
b dw 0
; a,b可以代表段中的内存单元
; 相当于mov ax, cs:[4]
mov ax, b
|




