
URL解析模式
1.URL解析
(1)分析
tp应用入口:https://severName/index.php/模块/控制器/操作/参数/值/
- serverName:在本地为
localhost/tp5/public/,部署后映射为域名 - 模块:位于根目录下的application下,默认下有一个index目录,它就是一个模块
- 控制器:在上面index目录(index模块)下有一个controller控制器目录,其中的Index.php就是一个控制器
- 操作:在控制器的类中的方法就是操作如上面Index.php中的两个方法:
index(),hello() - 参数 值:是对应上面操作的,如果操作有参数,则可以通过url传参
(2)实例
1 | //文件位置:/tp5/appliction/test/controller/Abc.php |
控制器名的首字母要大写如:Index,Abc。注意:如果控制器名初始化时首字母没有大写,之后改过来也无法生效了
如果方法的参数为$name,则url操作后面一定要加上
/参数/值/注意url的最后要有/
(3)关于环境
修改apache配置文件,开启伪静态,即可将index.php省略
模块设计
1.目录结构
tp5默认为多模块结构

模块下的类库文件命名空间统一为:app\模块名:
namespace app\test\controller\Index;当只有一个模块时,可以绑定这个模块:从而省略模块名
1
2// 文件位置:tp5/public/index.php
Container::get('app')->bind('test')->run()->send();
当只有一个模块,一个控制器时,可以绑定模块和控制器,从而省略模块/控制器
1
2
3//文件位置:tp5/public/index.php
Container::get('app')->bind('test/abc')->run()->send();
2.空模块
通过环境变量设置空模块,将不存在的目录统一指向指定目录
1 | // 文件位置:tp5/config/app.php |
空模块只有在多模块开启,没有绑定模块情况下生效
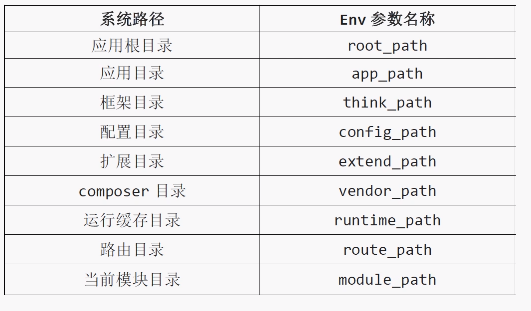
3.环境变量
tp5提供了一个类库Env来获取环境变量,如:return env('app_path')
控制器定义
1.控制器要点
- 可以继承控制器基类,方便使用功能,但不是必要的
- 如果控制器名有两个大写字母,如:class HelloWorld用
public/hello_world这样的方式访问 - 如果想改变根命名app,可以在根目录创建.env文件写上键值对,如:
app_namespace=application
2.渲染方式
(1)初始化渲染
1 | // 初始化渲染内容(无论有没有调用都会渲染出来),必须是继承了Controller |
(2)输出数组
1 | // 输出数组 |
(3)输出html模板
1 | // 模板输出,输出的是该模块文件下视图文件中的html文件 |
控制器操作
1.前置操作
可以灵活控制的页面初始化方法,需要继承至Controller类
1 |
|
2.跳转和重定向
Controller类提供了两个跳转方法:success(msg,url)和error(msg)
1 |
|
- 成功和失败都有一个固定的页面模板:’thinkphp/tpl/dispatch_jump.tpl’;
- 在config/app.php配置文件中可修改跳转页面对应的模板
3.空方法和空控制器
(1)空方法
在控制器中使用_empty方法可以自动拦截不存在的方法
1 | // 空链接(空方法) 拦截 |
(2)空控制器
在控制器文件下创建Error.php控制器,则可以处理控制器不存在的异常
1 |
|
数据库与模型
1.连接数据库
thinkphp 采用内置抽象层将不同的数据库进行封装处理
数据抽象层基于PDO模式,无需针对不同的数据库编写相应的代码
数据库的连接是在config的database.php配置文件下修改连接信息
1
2
3
4
5
6
7
8
9
10
11
12// 数据库类型
'type' => 'mysql',
// 服务器地址
'hostname' => '127.0.0.1',
// 数据库名
'database' => 'tp_data',
// 用户名
'username' => 'test',
// 密码
'password' => '123456',
// 端口
'hostport' => '',
2.控制器访问
在控制器中直接调用db类的方法查询数据库
1 | // 按表名查找数据库,必须加上前缀 |
3.模型访问
Model就是用来处理和配置数据库的相关信息
在模块中创建model文件夹,然后创建与表名对应的类(首字母大写)
1 |
|
配置好model与数据表的对应后,即可在控制器利用模型访问数据库
1 | // 使用模型访问数据库 |
查询数据
1.查询一条数据
1 | // 查询一条数据 |
2.数据查询异常处理
主要使用findOrFail()抛出一个错误,catch语句才能捕捉到异常
1 | // 数据不存在时异常处理 |
3.查询多例数据
1 | // 查询多列数据 |
4.返回指定数据
1 | // 指定返回数据查询 |
链式查询
1.查询规则
1 | // 查询规则 |
2.链式的应用
1 | // 保存实例避免资源浪费(链式查询的特点,可以保存对象) |
增删改数据库
1.单条插入操作
1 | // 单条插入操作 |
2.批量插入操作
1 | // 批量插入操作 |
3.数据修改
1 | // 数据修改 |
4.函数处理数据修改
1 | // 利用mysql函数进行数据修改 |
5.删除数据
1 | // 删除数据 |
查询表达式
1.比较查询
1 | // 比较查询 |
2.模糊查询
1 | // 模糊查询(即模糊查询字符串) |
3.区间查询
1 | // 区间查询 |
4.多条查询
1 | // 多条查询 |
5.自定义查询
1 | // 自定义查询(可以自己构建sql查询语句) |
聚合查询
1.数值计算查询
1 | // 聚合查询 |
2.闭包查询
1 | // 子查询 |
常用链式方法
1.where():条件输出
1 | // where()链式方法 |
2.field() :指定字段输出
1 | // field()链式方法 |
3.limit():限制输出条数
1 | // limit()链式方法 |
4.page():输出分页
1 | // page()链式方法 |
5.group():数据分组
1 | // group()链式方法 |
6.having():分组条件输出
1 | // having()链式方法 |
模型定义
1.模型设置
1 | // 如果控制器中的类名和model的类名相同,就需要引入,设置别名 |
2.模型操作
(1)构建模型:
1 | // 模型名会自动对应到数据表 |
(2)控制器调用模型进行操作:
1 |
|
我们可以通过数据库类去操作数据库,但是这样无法使用模型的事件功能
模型添加与删除
1.插入一条数据
1 | // 利用模型进行数据添加(一条) |
2.批量插入数据
1 | // 利用模型批量插入数据 |
3.delete()删除数据
1 | // 数据删除delete()方法 |
4.destroy()删除数据
1 | // 数据删除destroy()方法 |
5.条件删除
1 | // 条件删除 |
模型更新与查询
1.数据修改
(1)get方法获取然后修改
1 | // get方法获取数据,然后修改 |
(2)where()+find()
1 | // where方法结合find()方法获得数据,然后修改 |
(3)save批量修改数据
1 | // 直接利用save更新数据 |
(4)静态方法更新
1 | // 利用数据库类库的静态方法进行修改 |
2.数据查询
模型:
1 | // 模型名会自动对应到数据表 |
控制器:
1 | // 数据查询 |
模型获取器与修改器
1.获取器
(1)模型获取器
在模型中
1 | // 获取器,修改返回字段的值(针对查询操作) |
在控制器中
1 | // 经过模型的获取器,返回数据 |
(2)动态获取器
1 | // 动态获取器,直接在控制端过滤数据 |
(3)获取器优先级比较
1 | // 获取器优先级比较 |
2.修改器
在模型中
1 | // 修改器,修改插入的值(针对插入操作) |
在控制器中
1 | // 经过修改器,插入数据 |
模型搜索器和数据集
1.模型搜索器
模型搜索器用于封装字段(或搜索标识)的查询表达式
2.模型数据集
模型数据集由all()和select()方法返回数据集对象
模型自动时间戳和只读字段
1.模型自动时间戳
系统自动创建和更新时间
2.模型只读字段
设置只读字段,该字段无法被修改
模型类型转换和数据完成
1.模型类型转换
通过在模型段设置写入或读取时字段类型进行转换
2.模型数据完成
模型中的数据可以通过auto,insert,update三种形式完成,设置自动填入默认值
模型查询范围和输出
1.模型查询范围
在模型段创建一个封装的查询或写入方法,方便控制器端调用(自定义查询)
2.模型输出方式
包括:模板输出,数组输出,Json输出
JSON字段
1.数据库JSON
在数据库的字段中,设数据类型为json类型,然后可以通过数组写入
2.模型JSON
使用模型的方法新增包含json数据的字段
软删除
软删除不是真正删除数据,而是给数据设置一个标记
1.数据库软删除
创建一个软删除时间的字段,填入时间标记
2.模型软删除
一般推荐使用模型端进行软删除
模板引擎和视图渲染
1.模板引擎
模板引擎渲染视图
模板引擎分成两种,一种是内置的,一种外置作为插件引入的(我们使用内置即可)
2.视图渲染
通过控制器,把模板引擎的模板页面(视图渲染)加载进来
视图赋值和过滤
1.视图赋值
在视图中给模板页面传递值
2.视图过滤
对模板输入的变量进行过滤
模板变量输出
1.变量输出
当模板文件位置创建好后,输出控制器为变量赋值,然后通过{$name}这样的方式在模板输出变量值
2.其他输出
模板中函数的使用和运算符
在前端模板页面使用函数和运算符达到灵活地渲染出动态数据
1.使用函数
提供一些函数方法对数据进行过滤处理,使用管道符进行调用
2.运算符
在模板中可以对数据进行运算处理
模板的循环标签
模板循环输出循环块,动态输出数据
1.foreach循环
控制器通过模型把数据列表筛选出来,再传递到视图,然后再将其渲染出来
2.volist循环
volist也是将查询的到的数据集通过循环的方式进行输出
3.for循环
for循环可以通过起始和终止值,结合步长实现循环
模板的比较和定义
1.比较标签
{eq}{/eq}标签,比较两个值是否相同,相同即输出包含内容
还存在其他不同的标签代替不同的关系运算符对变量进行比较
2.定义标签
在模板页面定义一个变量,可以使用{assgin}标签,
模板的条件判断标签
1.switch标签
实现多个条件判断
2.if标签
基本条件判断语句
3.范围标签
{in}和{notin},判断值是否存在或不存在指定的数据列表中
4.是否存在标签
是否存在:{present}和{notpresent}判断变量是否已经定义赋值
是否为空:{empty}和{notempty}判断变量是否为空值;
模板的加载包含输出
1.包含文件
使用{include}标签加载公用重复的文件,比如头部,尾部和导航部分
2.输出替换
在模板中常常需要调用一些静态文件,比如css/js。直接写完整的路径引入,比较冗长,所以需要把这些路径整理打包
3.文件加载
传统方式调用css或js文件时,采用link和script标签实现。tp5提供了{load}标签的方法加载css和js文件
模板的布局和继承
1.模板布局
默认不支持模板布局功能,需要在配置文件中开启
2.模板继承
模板继承的布局方法更加灵活,把内容和样式分离
路由介绍和定义
1.路由简介
路由的作用是让url地址更将规范优雅(tp的默认url确实有点过分了)
设置路由对url的检验,验证等一系列操作提供了极大的便利性
2.路由定义
为url自定义路由规则,让url访问更加简洁和优雅( •̀ ω •́ )✧
在route文件下定制自己专属的路由规则
路由的变量规则和闭包
1.变量规则
用户可以通过自定义的路由进行传值,我们通过设置变量规则对输入的值进行过滤出来
2.闭包支持
闭包支持可以让用户通过url直接执行语句,不需要通过控制器和方法
路由的地址和缓存
1.路由地址
路由的地址一般为:控制器/方法,如果是多模块则为:模块/控制器/方法
2.路由缓存
开启路由缓存可以极高提高性能,需要在部署环境下才有效果
路由的参数和快捷路由
1.路由参数
设置路由时,可以设置第三个数组参数,主要实施匹配检测和行为执行(比如检测文件类型,绑定到模型)
2.快捷路由
快捷路由可以快速给控制器注册路由,还可以更加不同的请求类型设置前缀
路由分组和注解
1.路由分组
将相同前缀的路由合并分组,这样可以简化路由定义,提高匹配效率
使用group方法进行分组路由注册
2.注解路由
tp5提供了一个可以在注解中直接创建路由的方式(默认关闭),在控制器写入路由注解可以达到在router.php写路由同样的效果
路由MISS和跨域请求
1.MISS路由
开启强制路由功能,匹配不到相应规则时自动跳转到MISS(控制器中的miss方法)
2.跨域请求
但不同域名进行跨域请求时,由于浏览器的安全限制,会被拦截
在路由中使用allowCrossDomain()方法可以解除跨域的限制(在restful api 这种前后端分离的架构上,这点尤为重要)
把域名限制添加到头部中可以限制访问的域名
路由的绑定和别名
1.路由绑定
路由绑定可以简化URL和路由规则的定义,可以绑定到模块/控制器/操作
2.路由别名
给控制器起一个别名,可以通过别名自动生成一系列规则
资源路由
采用固定的常用方法来实现简化URL功能
系统提供一个命令,方便开发者快速生成一个资源控制器(自动生成包括显示,增删改查等多个操作方法)
域名路由
1.域名路由
在电脑host文件中,添加域名映射
2.域名绑定
在配置文件app.php中可以设置根域名,如果实际域名不符,会解析失败(默认自动获取)
路由的URL生成
之前的URL都是我们手动设置的,tp5提供了一套自动生成的方法(控制器的方法中写入)
请求对象和信息
1.请求对象的获取
(1)继承控制器基类时,会自动被注入Request请求对象的功能
(2)自行注入Request请求对象(依赖注入)
(3)facade方式:应用于没有进行依赖注入的场合
(4)使用助手函数request()方法
请求变量
1.请求变量
Request对象支持全局变量的检测,获取和安全过滤(主要作用对象是url)
2.助手函数
使用助手函数对Request对象提供的方法进行简化
请求类型与请求头
1.请求类型
我们用method()方法判断Request的请求类型
2.Http头信息
使用header()方法输出http头信息,返回是数组类型
伪静态-参数绑定-请求缓存
1.伪静态
伪静态技术是指展示出来的是以html一类的静态页面形式,但其实是用动态脚本来处理的。
2.参数绑定
参数绑定功能:即通过url进行数据传参
3.请求缓存
请求缓存仅对GET请求有效,并设置有效期
响应重定向和文件下载
1.响应操作
(1)响应输出:return, json, view
(2)response方法可以设置第二参数:状态码,也可以调code()方法返回状态码
(3)通过header()设置头文件
2.重定向
使用redirect()方法可以实现页面重定向,需要return执行(即页面跳转)
3.文件下载
文件和图片下载都可以使用download()方法即可,路径为实际路径
容器和依赖注入
1.依赖注入
依赖注入本质上是指对类的依赖通过构造器完成自动注入
依赖注入:即允许通过类的方法传递对象,并约束了对象类型,二传递的对象背后的那个类被自动绑定并且实例化了
由于控制器的参数都来自于URL请求,普通变量通过参数绑定自动获取,对象变量则是通过依赖注入生成
2.容器
依赖注入的类统一由容器管理的,大多数情况下是自动绑定和自动实例化
在容器中可以通过bind()和app()来实现手动的绑定和实例化
Facade
1.创建静态调用
facade即门面设计模式,为容器的类提供了一种静态调用模式(比如之前使用的Request::,Route::,Db::等等)
在common文件创建容器,在facade文件创建静态调用方法对应common的方法
2.facade核心类库
上面仅仅是展示了facade运行的原理,在实际运用中我们使用系统提供的facade核心类库即可
钩子和行为
1.概念理解
行为:当执行到路由时,对路由的设置进行一系列的检测,这种就叫行为
钩子(事件):行为执行的位置点,触发点
2.实例展示
在behavior文件夹下,存放行为类,行为类中设置一个入口方法run(),只要钩子被触发就会执行
钩子需要在配置文件中的tags.php设置,把行为注册到其中
我们也可以在tags.php自定义自己的钩子
中间件
1.定义中间件
中间件与钩子类似,主要用于拦截和过滤HTTP请求(如URL重定向,权限验证),并进行相应处理
通过命令行,在应用目录下生成一个中间件文件
在配置文件夹下设置中间件配置文件:middleware.php(默认说没有的)
2.前/后置中间件
前置中间件就是请求阶段进行拦截验证,比如登录判断,跳转,权限等
后置中间件就是请求完毕后在进行验证,比如写入日志
3.路由中间件
给路由使用的中间件,当检测到路由含指定条件,就触发这个中间件
4.控制器中间件
可以在控制器中注册中间件,控制器必须继承Controller基类
异常处理
1.异常处理
(1)使用Exception手动抛出异常
(2)try……cacth对异常捕捉并抛出
(3)用HttpException手动抛出http异常
(4)系统上线要关闭调试模式,进入部署环境下,可以在配置文件设置http错误页面
日志处理
日志处理由Log类完成,记录所有程序中运行的错误记录
系统的报错会自动存入日志中,我们也可以手动添加日志
数据验证
1.验证器
系统提供了一条命令直接生成验证器类
在类中我们可以设置规则,定义错误信息
默认情况下,一旦数据验证不符合规则,就会立即停止验证进行返回
2.验证规则
验证规则有字符串模式和数组模式两种
独立验证(手动调用验证类),直接在控制器中设置验证规则而无需通过验证器
独立验证支持闭包模式,部支持属性方式和多规则方式
3.验证场景
有时我们并不希望所有的字段都得到验证,这是可以设置一个$scene属性,用来限定场景验证
比如做插入操作时验证3个字段,而做修改操作时只验证两个字段
4.路由验证
在路由的参数来调用验证类进行验证,和字段验证一样
在路由中绑定验证器
也可以在路由中写入独立的验证器
验证静态调用和令牌
1.静态调用
使用facade模式进行调用验证,非常适合单个数据验证
2.表单令牌
表单令牌就是在表单中增加一个隐藏字段,随机生成一串字符,确认提交的表单不是伪造
这种随机产生的字符和服务器的seesion进行对比,通过则是合法表单
独立验证和内置规则
1.独立验证
除了之前提过的独立验证,系统还提供了make方法实现独立验证(tp6废弃)
2.内置规则
内置规则说系统准备的常用验证规则,而且严格区分大小写
数据库与模型
Seesion
session第一次调用时,会按照config/seesion.php进行初始化
也可以在控制器中设置初始化
使用::set()和::get()方法设置seesion的存取
助手函数也有对应的替代方法
Cookie
cookie在配置文件cookie.php中会自行初始化
::set()创建一个基本cookie
分页功能
数据库操作和模型操作,都使用paginate()方法来实现
上传功能
Request::file方法文件接收文件,然后调用move方法将文件移动到指定文件夹
可以设置验证器,用于验证文件大小类型等
默认情况下,上传文件是按时间生成命名的
数据库和模型的事件
1.数据库事件
当对数据库进行增删改查时,可以触发一些事件进行额外操作,它们可以部署在构造方法中等待激活执行
在控制器端,事件一般可以写在构造方法中,统一管理
2.模型事件
在模型端,创建init()方法,写入模型事件,可以使用event或快捷方式
关联模型
关联模型,就是将表与表之间进行关联和对象化,更高效的操作数据
1.一对一关联
(1)hasOne模式
模型端使用hasone方法创建一对一关联关系,参数1为附表名,参数2为外键,参数3为主键
hasOmne模型适合主表关联附表
在关联表中,->profile属性方式可以修改数据,删除数据,->profile()方法方式可以新增数据
2.一对多关联
hansMany适合主表关联附表,实现一对多查询,可以查多个重复外键的数据
使用->profile()方法模式加上where可以进一步筛选数据
也可以通过has()和haswhere()通过关联附表查询主表
3.关联预载入
在关联查询中,当查询次数过大时,我们可以使用关联预载入进行封装,使多次查询变成一次查询
使用with方式进行关联
关联预载入减少查询次数提高了性能,但不支持多次调用
4.关联统计和输出
关联统计:
- 使用withCount()方法可以统计主表关联附表的个数
- 使用withMax()等统计主表关于附表的字段统计
关联输出:
隐藏,显示,添加主表字段或附属表字段,然后输出
5.多对多关联查询
一对一场景:一个用户对应一个档案资料(至少两张表)
一对多场景:一个用户可以有多条评论(至少两张表)
多对多场景:一个用户对应多个角色,而一个角色对应多个用户(至少三张表)
多对多关联使用belongsToMany方法,填入其他两个附表模型信息作为参数数