
idea基本设置
File>Setting打开idea基本设置,可以更改字体主题,安装插件等
建议安装中文翻译插件和Codota插件
idea创建项目
1.参考文章
语言版本和环境版本不一致导致错误:Error:java: 无效的源发行版
2.注意事项
(1)配置
新建一般Java项目时,一般选择默认配置进行
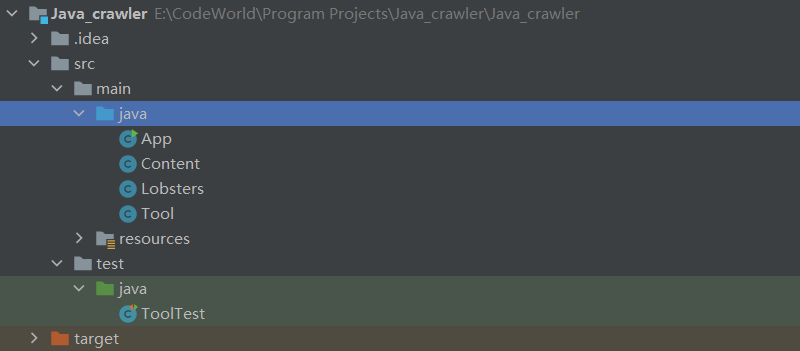
(2)打开项目
打开的项目文件时,文件结构如下,文件路径多出一层或少一层文件,idea都不能识别出该项目(程序文件都要放到src文件中):
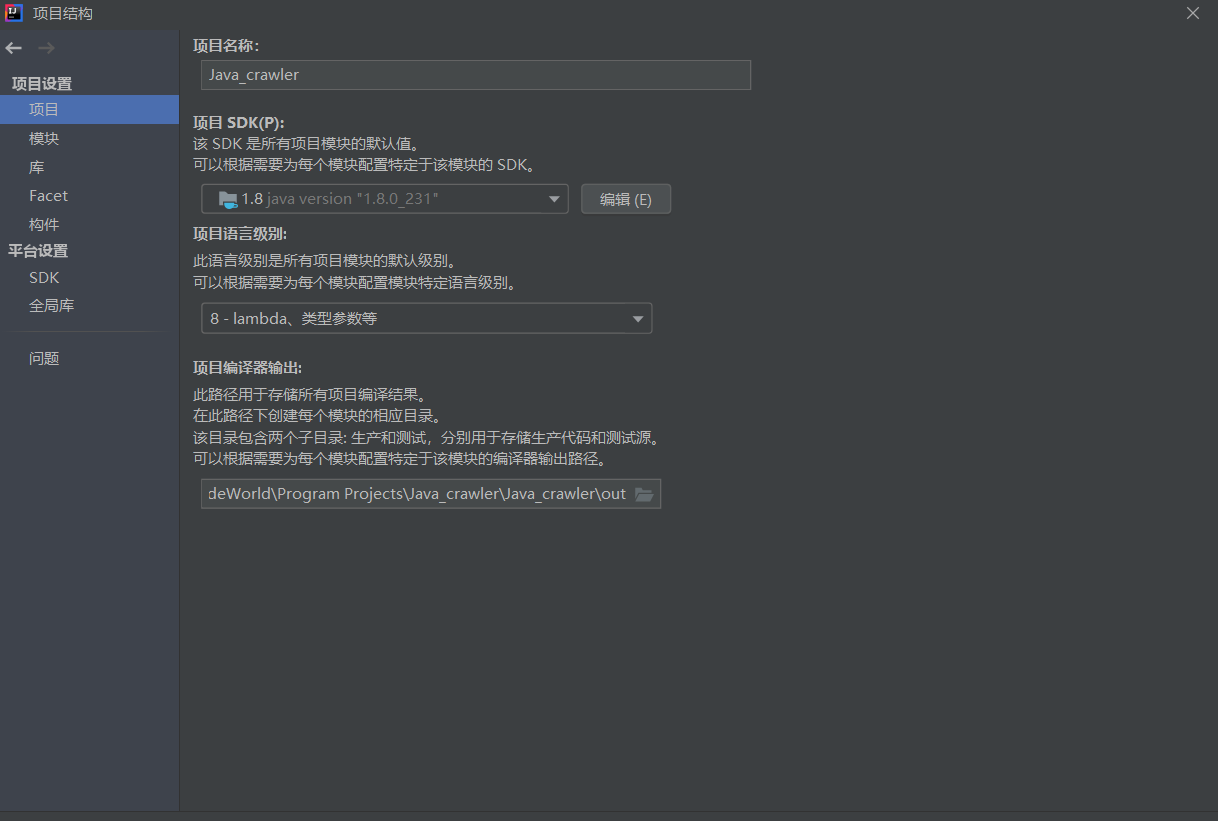
(3)配置修改
项目结构(文件 > 项目结构)中可以修改项目的一些配置(可设置项目,模块的语言级别)
(4)标记目录
标记目录可以自定义源根目录等,一般不改动,默认src为源根目录
(5)添加Maven框架
在Java一般项目中没有meavn的选项,可以在后期加上Maven框架支持
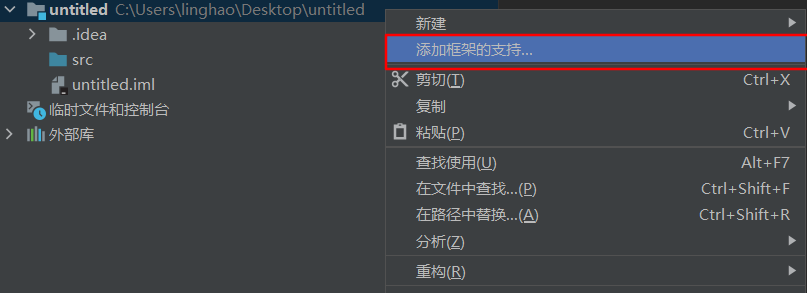
添加了Maven框架后,还需要重新加载Maven项目即可完成框架添加
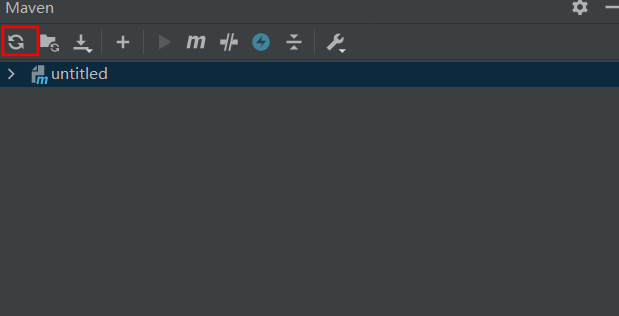
配置meavn
1.参考文章
2.注意事项
(1)maven配置
idea有自己自带的maven,如果想自定义到自己下载的maven文件,可以在设置中修改(这样的修改只是针对该项目,新建的项目还是使用默认的maven)
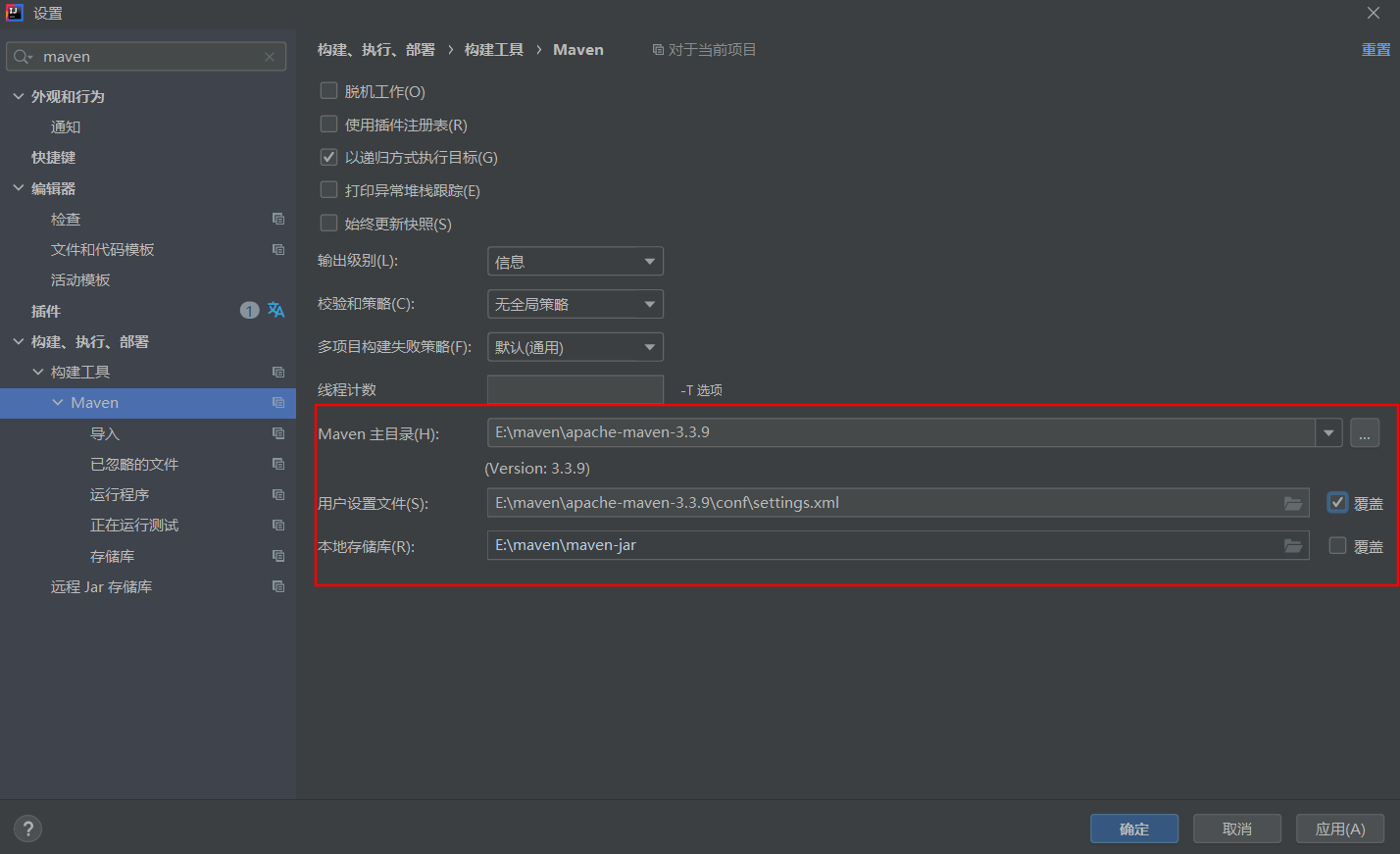
- 设置主目录
- 用户设置文件指向maven的setting文件
- 可以新建一个文件用于存储本地库
(2)Meavn创建项目
除了在一般项目创建后再添加Maven框架,我们也可以直接使用Meavn框架创建项目
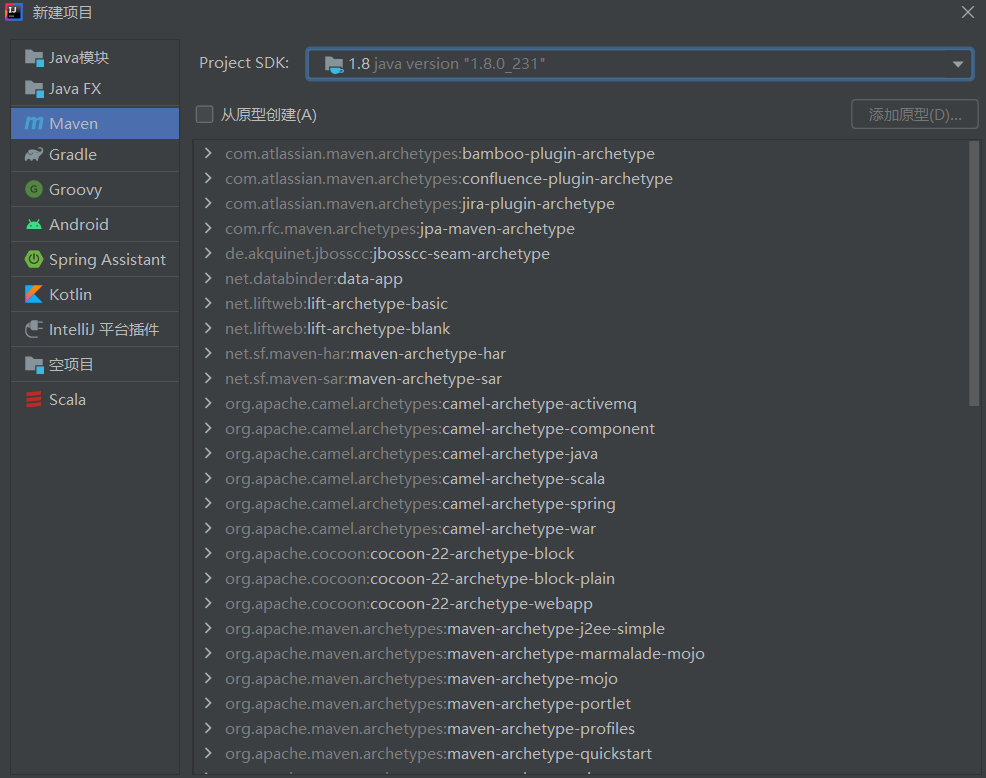
区别于一般的Java项目,使用Meavn框架创建的会在src新建两个文件夹:main(放主程序)和test(放测试程序)
(3)meavn添加包
- 通过pom.xml添加依赖
在pom.xml文件中添加<dependency></dependency>标签,如下
1 | <dependency> |
要注意要是在<dependencies></dependencies>内添加依赖
我们可以通过Maven Repositor查找对应包的依赖项xml文本
最后加载Maven包变更完成依赖项的添加
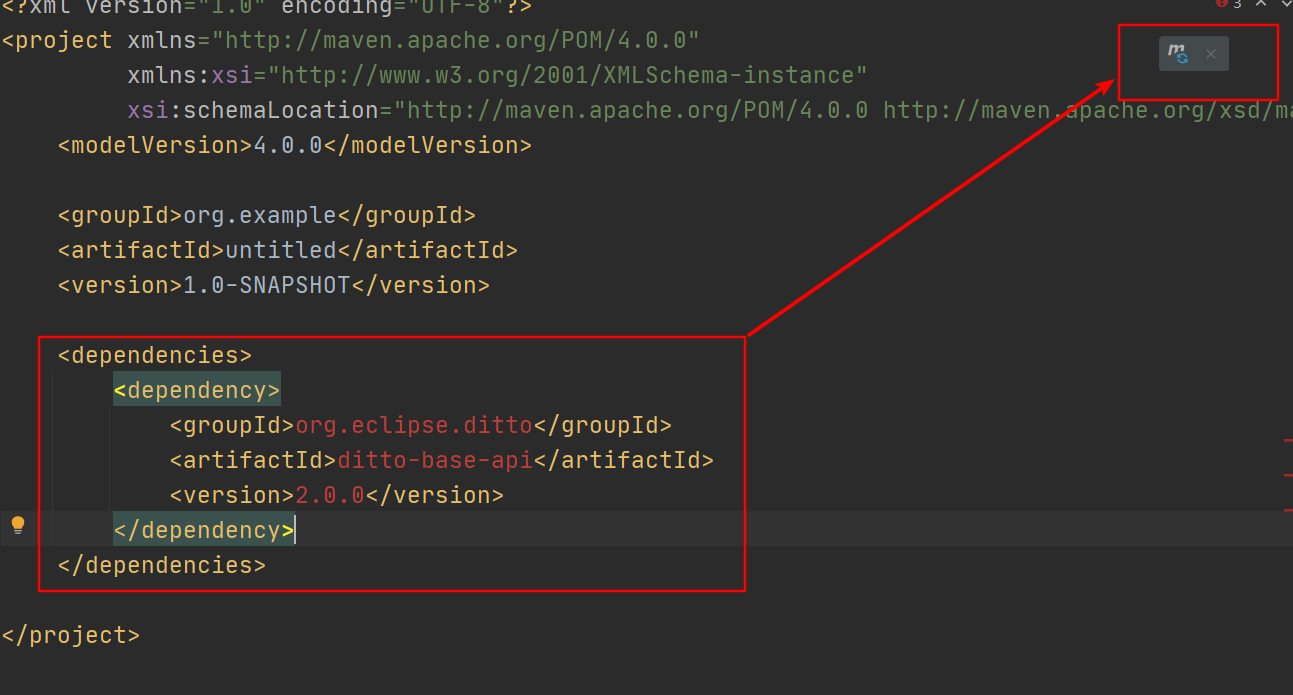
- 手动添加jar包
meavn找不到相关包时,可以直接下载jar文件到本地包,放在刚刚设置Maven本地库存储文件中,然后使用maven导入
爬虫配置
1.参考文章
出现了SLF4J的报错解决方法:添加依赖即解决
2.注意事项
(1)爬虫框架添加
爬虫框架采用了易于上手的WebMagic框架,在pom.xml文件中添加相关依赖
1 | <dependency> |
(2)无法爬取网页
无法爬取TLS1.2协议站点的问题
在依赖中把WebMagica改成最新版本(0.7.4以上)即可解决
(3)SLF4J报错
出现了SLF4J报错可以添加以下依赖
1 | <dependency> |
(4)爬取方法
- 实现实现PageProcessor接口,设置爬虫相关配置
1 | private Site site = Site.me() |
- process编写抽取逻辑,可以定义爬取页面的规则
1 | public void process(Page page){ |
- Spider类执行爬虫
1 | Spider.create(obj) |
(5)正则匹配问题
WebMagic链式抽取元素中使用的正则是不区分大小写的
调试方法
1.参考文章
2.单元测试
(1)单元测试理解
单元测试实质上是在主运行程序之外,为某个方法创建单独的测试程序,而不必只有一个执行入口进入程序
(2)单元测试特殊情况
抽象方法在单元测试时不能被调用,因为抽象类不能有实例不能直接调用
(3)单元测试使用案例
1 | // 爬取工具类测试 |
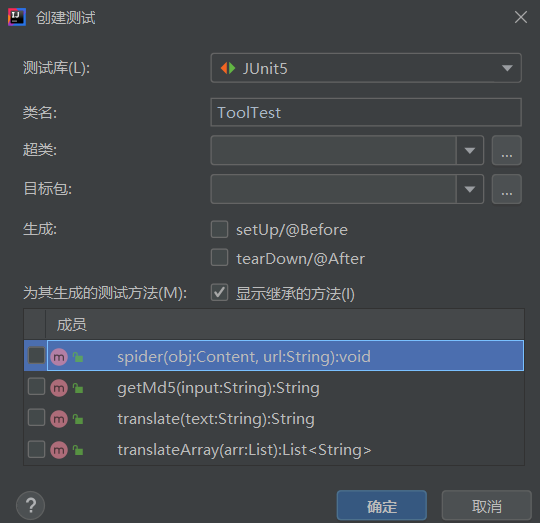
(4)单元测试生成
idea可以快捷为类生成一个测试类,并可以勾选生成测试方法
3.单步调试
(1)断点设置
设置断点可以让程序在调试时从入口开始执行到断点所在代码
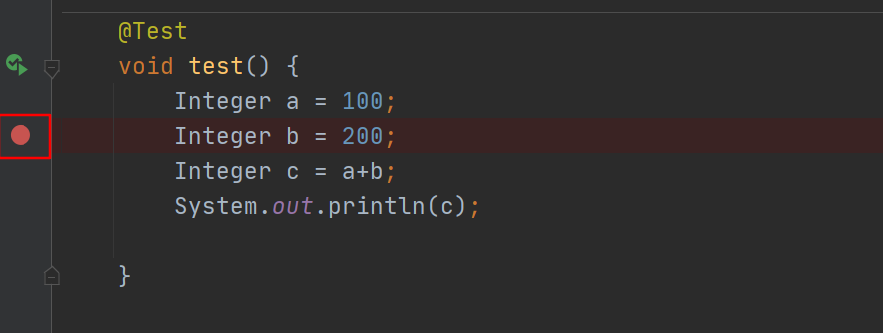
不设断点调试,程序会执行完全部代码,无法实现单步调试
(2)调试显示
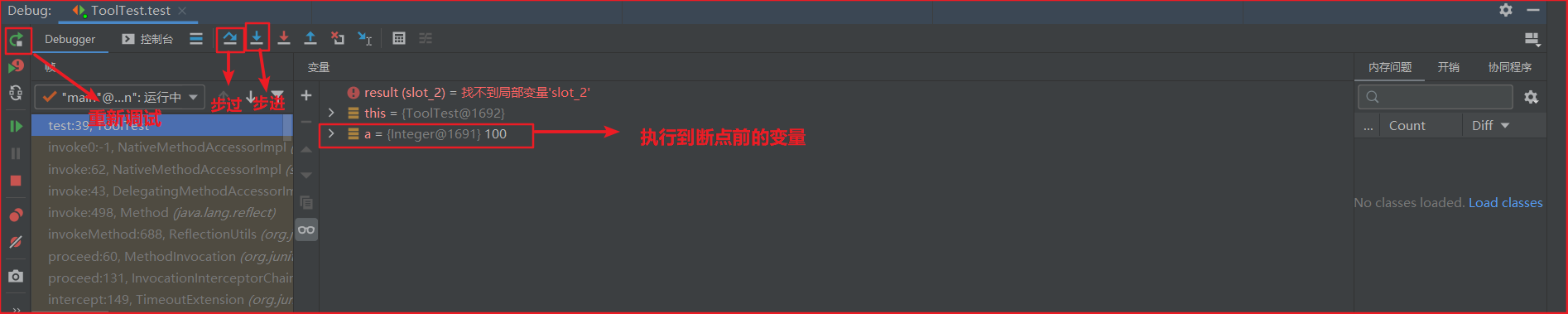
- 重新调试:当单步调试进入加载类等奇怪的地方时,可以重新调试,直到断点出现勾号,说明调试成功
- 调试过程中,步过(Setp Over)使用频率最高,当碰到方法时,不会进入方法内,而是直接调用方法,然后进入下一行
- 步进( Step Into)则会进入方法内
构造子类
1.参考文章
2.注意事项
(1)子类属性继承问题
子类是继承了父类的私有属性和私有方法,只是子类没有权限直接访问父类的私有属性和私有方法。但是我们可以通过继承父类get和set方法访问到父类的私有属性
1
2
3
4
5
6
7
8
9// 修改私有属性方法
public void set_title(List title){
this.title = title;
}
// 访问私有属性方法
public List show_title(){
return this.title;
}父类属性不可被重写,只会被调用,父类方法可以被重写,也可以被调用
当子类中存在和父类同名属性,父类属性会隐藏起来,在多态的情况下属性被调用时会激活父类属性子类属性隐藏起来,而方法不会隐藏,一旦被重写,只能使用super来在子类调用
(2)继承中this指向问题
- 对于方法的覆盖,new的谁就调谁,这就是多态。
- 对于成员变量的覆盖,this在哪个类就指向哪个类的成员变量,没有多态。
- 无论子类是否覆盖成员变量,this始终访问父类的成员变量
- 静态方法中,无法使用this引用上下文内容(属性,方法)
(3)抽象方法使用问题
- 抽象类是作为一个模板存在的,不能创建抽象类对象,需要用子类实现所有其抽象方法后变为非抽象类才能间接实例化
- 抽象方法只有声明没有实现(对于不知道该怎么实现的方法,我们可以声明为抽象方法),强制子类必须重写抽象方法
Http请求
1.参考文章
2.注意事项
(1)Http请求实现
get请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18String urlNameString = url + '?' + param;
URL realUrl = new URL(urlNameString);
// 打开链接,强转换为httpURLConnection类
URLConnection connection = realUrl.openConnection();
// 设置通用请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际链接
connection.connect();
// 请求成功获得输入流
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
// 获得返回结果
String res = in.readLine();
post请求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection conn = realUrl.openConnection();
// 设置通用的请求属性
conn.setRequestProperty("accept", "*/*");
conn.setRequestProperty("connection", "Keep-Alive");
conn.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 发送POST请求必须设置如下两行
conn.setDoOutput(true);
conn.setDoInput(true);
// 获取URLConnection对象对应的输出流
out = new PrintWriter(conn.getOutputStream());
// 发送请求参数
out.print(param);
// flush输出流的缓冲
out.flush();
// 定义BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(conn.getInputStream()));
//获得返回结果
String res = in.readLine();
- Java发起http请求后,返回值为String类型
- 注意请求api的QPS(每秒请求量),我们可以通过
Thread.currentThread().sleep(1000);//毫秒简单实现延时 - 链接编码问题,有时候链接请求失败是因为空格没有编码为%20,而导致请求失败
(2)Java加密问题
实现md5加密
1 | // md5加密工具 |
Java数据处理
1.参考文章
2.注意事项
(1)字符串与数组转换
字符串转换成数组
String.split() 方法,Java 中通常用 split() 分割字符串,返回的是一个数组
1
2
3
4
5String str = "123abc";
String[] arr = str.split("");
for (int i = 0; i < arr.length; i++) { // String数组
System.out.print(arr[i]); // 输出 1 2 3 a b c
}数组转换为字符串
1
2
3
4
5
6
7String[] arr = { "123", "abc" };
StringBuffer sb = new StringBuffer();
for (int i = 0; i < arr.length; i++) {
sb.append(arr[i]); // String并不拥有append方法,所以借助 StringBuffer
}
String sb1 = sb.toString();
System.out.println(sb1); // 输出123abc
(2)数组遍历方法
传统for循环方法
for each循环(foreach只能用于普通数组)
利用Array类中的toString方法(不能直接打印数组,
System.out.println(array)这样打印是的是数组的首地址)1
2int[] array = {1,2,3,4,5};
System.out.println(Arrays.toString(array))
(3)List遍历方法
- 迭代器遍历(hasNext和next方法)
- for each遍历(从List中获得的元素是对象)
- 传统for循环遍历(使用size方法获得List长度)
- Lambda表达式
(3)Java中的正则表达式
- 注意该正则方法,一定是先find后group,group()方法通过前一个成功的find()方法调用返回找到的字符串
(5)List与Array的转换
List to Array
使用List 提供的toArray的接口对List进行转换
1
2// 指定类型转换
String[] array=list.toArray(new String[list.size()]);Array to List
使用ArrayList的构造方法进行转换
1
List<String> list = new ArrayList<String>(Arrays.asList(array));