Go的吉祥物Gopher也太可爱了叭!!!
参考文章:
Go语言标准库:https://studygolang.com/pkgdoc
Go案例代码:https://gobyexample-cn.github.io/
Go语言学习手册:https://www.topgoer.com/
HelloGo 1.Golang的主要特征
自动立即回收
更丰富的内置类型
函数多返回值
错误处理
匿名函数和闭包
类型和接口
并发编程
反射
语言交互性
2.第一个Go程序 1 2 3 4 5 6 7 8 9 10 package mainimport "fmt" func Hello () fmt.Println("HelloGo" ) }
3.Go的值运算 1 2 3 4 5 6 7 8 9 10 11 12 13 func Value () fmt.Println("go" +"lang" ) fmt.Println("go" ,"lang" ) fmt.Println("1+1=" , 1 +1 ) fmt.Println("7.0/3.0" ) fmt.Println(true && false ) fmt.Println(true || false ) fmt.Println(!true ) }
运行结果:
变量与常量 1.变量 (1)标准声明 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 var a = "TestString" fmt.Println(a) var b, c int = 1 , 2 fmt.Println(b, c) var d = true fmt.Println(d) var e int fmt.Println(e)
(2)批量声明 1 2 3 4 5 6 var ( a string b int c bool d float32 )
(3)短变量声明 1 2 3 f := "apple" fmt.Println(f)
2.常量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 const s string = "constant" func Constants () fmt.Println(s) const n = 500000 const d = 3e20 / n fmt.Println(d) fmt.Println(int64 (d)) fmt.Println(math.Sin(n)) }
常量的声明只是将变量声明中的var更改为const
基本数据结构 1.数组Array (1)声明默认数组 1 2 3 4 5 6 7 8 var a [5 ]int fmt.Println(a) a[4 ] = 100 fmt.Println(a) fmt.Println(a[4 ]) fmt.Println(len (a))
(2)声明并初始化数组 1 2 3 4 5 b:= [5 ]int {1 , 2 , 3 , 4 } c:= [...]int {1 , 2 , 3 , 4 , 5 , 6 } fmt.Println(b, c)
(3)声明二维数组 1 2 3 4 5 6 7 8 9 var twoD [2 ][3 ]int for i := 0 ; i < 2 ; i++{ for j:=0 ; j < 3 ; j++ { twoD[i][j] = i + j } } fmt.Println(twoD)
2.切片Slice (1)切片简介
切片是 Go 中的一种关键数据类型(引用类型),它为序列提供了比数组更强大的接口
切片的长度可以改变,因此,切片是一个可变的数组
切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制
(2)切片一般声明 1 2 3 4 var s1 []int s2 := []int {2 ,4 ,5 } fmt.Println(s1, s2)
(3)make创建 1 2 3 4 5 6 s3 := make ([]string , 5 , 6 ) fmt.Println(s3) fmt.Println(len (s3),cap (s3))
(4)切片赋值与追加 1 2 3 4 5 6 7 8 9 10 11 s3[0 ] = "a" s3[4 ] = "b" fmt.Println(s3) s3 = append (s3, "d" ) s3 = append (s3, "e" ,"f" ) s3 = append (s3, s3...) fmt.Println(s3)
(5)切片复制 1 2 3 4 c := make ([]string , len (s3)) copy (c, s3)fmt.Println(c)
(6)由数组或切片获得切片 1 2 3 4 5 6 7 l := s3[5 :7 ] fmt.Println(l) l = s3[:len (s3)-1 ] fmt.Println(l)
3.Map (1)map的创建 1 2 3 m := make (map [string ]int ) m1 := make (map [int ]string )
(2)map初始化 1 2 3 n := map [string ]string {"foo" :"str1" , "bar" :"str2" } fmt.Println(n)
(3)map赋值与取值 1 2 3 4 5 6 7 8 9 10 11 12 m["k1" ] = 7 m["k2" ] = 10 m1[1 ] = "test1" m1[10 ] = "test2" fmt.Println(m) fmt.Println(m1) v1 := m["k1" ] fmt.Println(v1)
不存在取值的返回:
1 2 3 4 prs := m["k2" ] _,prs2 := m["k2" ] fmt.Println(prs, prs2)
(4)map删除操作 1 2 3 delete (m, "k2" )fmt.Println(m)
基本流程控制 1.if语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func If (str string ) if str=="IfA" { fmt.Println("a条件" ) }else { fmt.Println("其他条件" ) } if str = "IfA" ; str=="IfA" { fmt.Println("a条件满足" ) } }
2.switch语句 (1)使用变量作为判定条件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 i := 2 fmt.Println("write" , i, "as" ) switch i { case 1 : fmt.Println("one" ) case 2 : fmt.Println("two" ) case 3 : fmt.Println("three" ) }
(2)使用函数返回的变量值作为expression 1 2 3 4 5 6 7 8 9 10 switch time.Now().Weekday(){ case time.Saturday, time.Sunday: fmt.Println("weekend" ) default : fmt.Println("weekday" ) }
(3)使用函数返回值的变量作为constant-expression 1 2 3 4 5 6 7 8 9 10 11 12 13 t := time.Now() switch { case t.Hour() >= 6 && t.Hour() < 8 : fmt.Println("清晨" ) case t.Hour() >= 8 && t.Hour() < 12 : fmt.Println("早上" ) default : fmt.Println("其他时间" ) }
3.for语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func For () i := 1 for i <= 3 { fmt.Println(i) i = i + 1 } for j := 7 ; j <= 9 ; j++{ fmt.Println(j) } for { fmt.Println("loop" ) break } for n:= 0 ; n <= 5 ; n++{ if n%2 == 0 { continue } fmt.Println(n) } }
4.Range语句 (1)Range简介
range类似迭代器操作,返回 (索引, 值) 或 (键, 值)
range 格式可以对 slice、map、数组、字符串等进行迭代循环
(2)数组遍历 1 2 3 4 5 6 7 8 nums := []int {2 , 3 , 4 } sum := 0 for _, num := range nums{sum += num } fmt.Println(sum)
(3)map遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 kvs := map [string ]string {"a" :"Ava" , "b" :"Bella" , "c" :"Carol" , "d" :"Diana" , "e" :"Eileen" } for k, v := range kvs{ fmt.Printf("%s : %s\n" , k, v) } for k := range kvs{ fmt.Println(k) } for _,v := range kvs{ fmt.Println(v) }
函数 1.多参数 (1)两参数 1 2 3 4 5 func plus (a int , b int ) int return a + b }
(2)同类型多参数 1 2 3 4 5 6 7 8 9 func plusPlus (a, b, c int ) string a1 := strconv.Itoa(a) b1 := strconv.Itoa(b) c1 := strconv.Itoa(c) return a1 + b1 + c1 }
(3)可变参数 1 2 3 4 5 6 7 8 9 10 11 12 13 func sum (str string , nums ...int ) fmt.Println(str, nums) total := 0 for _,num := range nums{ total += num } fmt.Println(total) }
2.多返回值 1 2 3 4 5 6 7 8 func vals (a, b int ) (int , int ) add := a + b sub := a - b return add, sub }
3.闭包函数 (1)声明 1 2 3 4 5 6 7 8 9 10 11 12 func intSeq () func () int i := 0 return func () int i++ return i } }
(2)调用 1 2 3 4 5 6 7 8 nextInt := intSeq() fmt.Println(intSeq()) fmt.Println(nextInt()) fmt.Println(nextInt()) nextInt2 := intSeq() fmt.Println(nextInt2())
(3)结果
4.递归函数 1 2 3 4 5 6 7 8 9 10 11 func fact (n int ) int if n == 0 { return 1 } return n * fact(n-1 ) }
指针 1.函数中的指针参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func zeroval (ival int ) ival = 0 } func zeroptr (iptr *int ) fmt.Println(iptr) *iptr = 0 }
2.调用与运行结果 1 2 3 4 5 6 7 8 9 i := 1 zeroval(i) fmt.Println(i) zeroptr(&i) fmt.Println(i) fmt.Println(&i)
运行结果:
结构体 1.结构体简介 Go语言中没有“类”的概念,也不支持“类”的继承等面向对象的概念。Go语言中通过结构体的内嵌再配合接口比面向对象具有更高的扩展性和灵活性
2.结构体实例化 (1)声明结构体 1 2 3 4 5 6 7 type person struct { name string age int }
(2)结构体实例化 1 2 3 4 fmt.Println(person{"Bob" , 20 }) s := person{name: "Sean" , age: 50 } fmt.Println(s.name)
输出结果
(3)结构体地址 1 2 3 4 fmt.Println(&person{name: "Ava" }) sp := &s fmt.Println(sp)
输出结果
3.构造函数 (1)构造方法 1 2 3 4 5 6 7 8 9 10 func newPerson (name string ) *person p := person{name:name} p.age = 42 return &p }
(2)调用与结果 1 fmt.Println(newPerson("Bella" ))
输出结果
4.结构体方法
对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
对于方法(如struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法
为了减少内存开销,一般用指针类型作为接收者,用指针变量调用方法
(1)定义结构体 1 2 3 4 type rect struct { width, height int }
(2)指针接收类型方法 1 2 3 4 func (r *rect) area () int return r.width * r.height }
调用:
1 2 3 4 5 fmt.Println("area" , r.area()) rp := &r fmt.Println("area" , rp.area())
运行结果:
(3)值接收类型方法 1 2 3 4 5 6 func (r rect) perim () int return 2 * r.width + 2 * r.height }
调用:
1 2 3 4 fmt.Println("perim" , r.perim()) fmt.Println("perim" , rp.perim())
运行结果:
接口 1.接口简介
接口(interface)定义了一个对象的行为规范,只定义规范不实现,由具体的对象来实现规范的细节
interface是一组method的集合,是duck-type programming的一种体现。接口做的事情就像是定义一个协议(规则)
2.接口的实现 (1)定义接口 1 2 3 4 5 6 type Gemoetry interface { area() float64 perim() float64 }
(2)构建结构体(用于生成对象) 1 2 3 4 5 6 7 8 9 type rect2 struct { width, height float64 } type circle struct { radius float64 }
(3)结构体的方法实现接口 只要对象实现了接口中所有的方法,就是实现了这个接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func (r rect2) area () float64 return r.width * r.height } func (r rect2) perim () float64 return 2 *r.width + 2 *r.height } func (c circle) area () float64 return math.Pi * c.radius * c.radius } func (c circle) perim () float64 return 2 * math.Pi * c.radius }
(4) 结构体实例化生成对象 1 2 3 4 5 6 7 8 9 10 var x Gemoetryx = rect2{width: 3 , height: 4 } fmt.Println(x.area()) fmt.Println(x.perim()) x = circle{radius:5 } fmt.Println(x.area()) fmt.Println(x.perim())
异常处理 go语言通过显式的返回值传递错误
1.内置接口返回错误信息 1 2 3 4 5 6 7 8 9 10 11 func f1 (arg int ) (int , error) if arg == 42 { return -1 , errors.New("can't work" ) } return arg + 3 , nil }
2.自定义结构体 (1)定义结构体 1 2 3 4 5 type argError struct { arg int prob string }
(2)定义结构体方法 1 2 3 4 5 func (e *argError) Error () string return fmt.Sprintf("%d - %s" , e.arg, e.prob) }
(3)异常测试方法 1 2 3 4 5 6 7 8 9 10 11 func f2 (arg int ) (int , error) if arg == 42 { return -1 , &argError{arg, "cam't work with it" } } return arg + 3 , nil }
(4)测试用例 1 2 r,e = f2(42 ) fmt.Println(r, e)
运行结果:
并发编程 1.Goroutines(协程) (1)协程简介
go func()这种形式即可实现创建一个新的协程执行函数一般函数调用是阻塞主线程的,即为同步;而使用协程调用函数,则会与主线程,其他协程一起运行,则是一个异步的过程
在并发编程中,不能用顺序执行语句的同步思维。在多个程序同时运行时,要考虑到各个协程开始的时间和结束的时间决定的运行结果,各个协程对同一数据的同时操作,各个协程任务同步,以及主线程结束后会关闭其他协程(不管其任务是否执行完毕)的问题
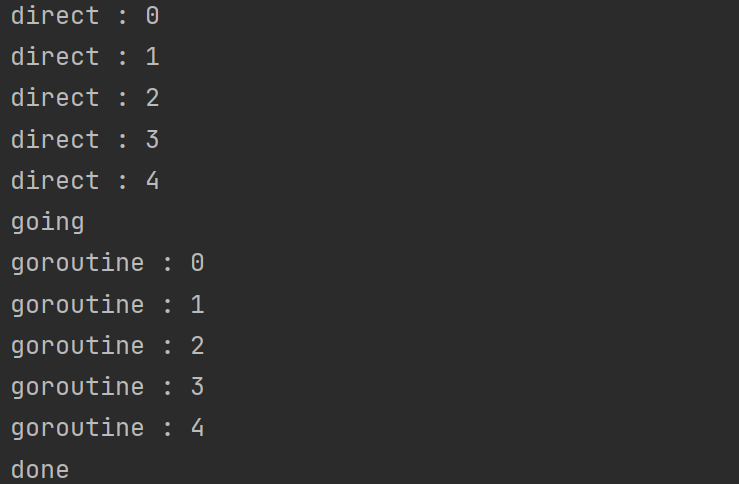
(2)运行案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func f (from string ) for i := 0 ; i < 5 ; i++{ fmt.Println(from, ":" , i) } } func Goroutines () f("direct" ) go f("goroutine" ) go func (msg string ) fmt.Println(msg) }("going" ) time.Sleep(time.Millisecond) fmt.Println("done" ) }
运行结果:
2.Channels(通道) (1)通道简介
通过goroutines可以实现函数并发运行,而这些并发执行的函数可以通过channels交换数据
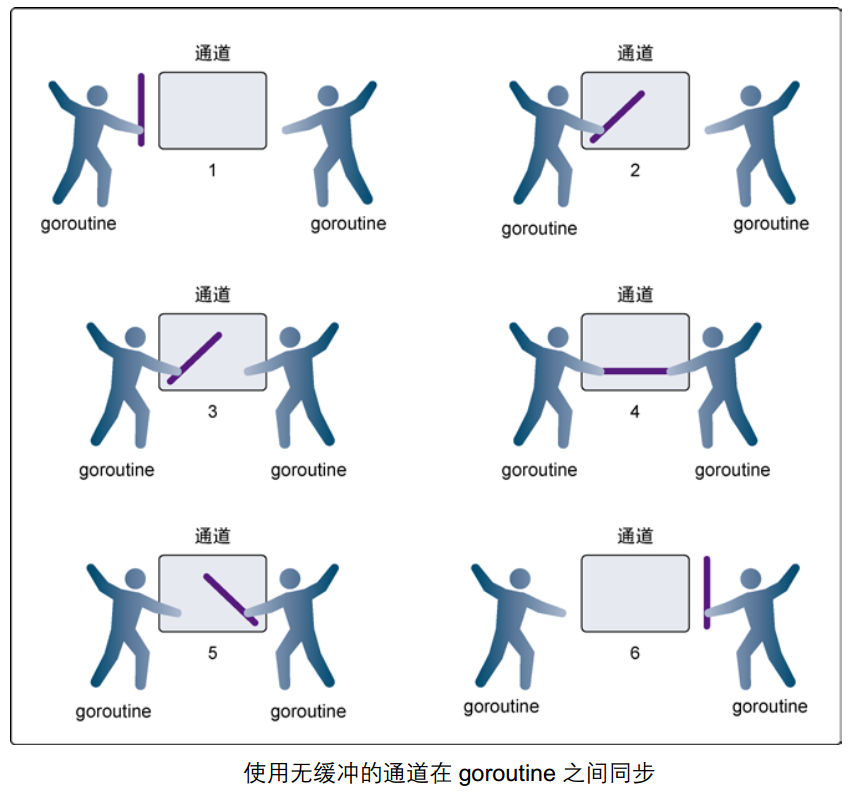
默认情况下,通道是无缓冲的(阻塞通道),无缓冲的通道必须有接收才能发送
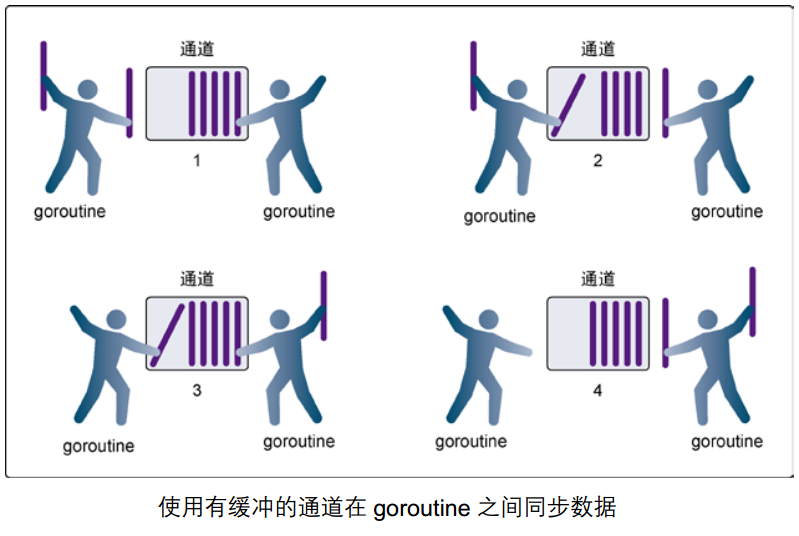
使用make函数初始化通道的时候为其指定通道的容量即可生成有缓冲通道
(2)通道的发送与接收 1 2 3 4 5 6 7 8 9 10 11 messages := make (chan string ) fmt.Println(reflect.TypeOf(messages), messages) go func () "ping" }()msg := <-messages fmt.Println(reflect.TypeOf(msg), msg)
运行结果:
(3)无缓冲通道 1 2 3 4 ch := make (chan int ) ch <- 10 fmt.Println("发送成功" )
运行结果:
无缓冲通道原理图:
无缓冲相当于小区没有快递点,快递员必须亲自把这个物品送到你的手上
(4)有缓冲通道 1 2 3 4 5 6 ch := make (chan int , 2 ) ch <- 10 ch <- 20 fmt.Println("发送成功" )
有缓冲通道原理图:
有缓冲通道相当于小区有个菜鸟驿站(非广告)或代收点帮你存快递,需要时再去取快递
(5)信道同步 在协程中存在着主线程结束后不管子协程有没有完成任务仍然让其强制下班的问题
虽然可以通过时间延迟让主线程嗯等,但是这种硬性处理方式浪费资源
通过信道,我们可以让主线程等待子协程发送任务完成的信号再结束自己的生命
子协程任务:
1 2 3 4 5 6 7 8 9 func worker (done chan bool ) fmt.Println("working" ) time.Sleep(time.Second) fmt.Println("done" ) done <- true }
主线程的运行:
1 2 3 4 5 done := make (chan bool , 1 ) go worker(done)<- done
(6)单向通道 将通道作为参数在多个任务函数间传递时,限制通道在函数中只能发送或只能接收
单向通道通信方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 func ping (pings chan <-string , msg string ) pings <- msg } func pong (pings <-chan string , pongs chan <-string ) msg := <-pings pongs <- msg }
单向通道的使用:
1 2 3 4 5 6 7 8 9 10 pings := make (chan string , 1 ) pongs := make (chan string , 1 ) ping(pings, "passed message" ) pong(pings, pongs) fmt.Println(<-pongs)
3.通道操作 (1)通道关闭 通道关闭这个信息也可以被接收到
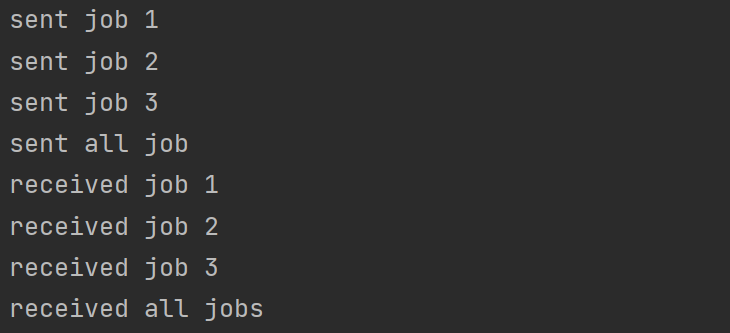
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 func Close () jobs := make (chan int , 5 ) done := make (chan bool ) go func () for { j, more := <-jobs if more { fmt.Println("received job" , j) } else { fmt.Println("received all jobs" ) done <- true return } } }() for j := 1 ; j <= 3 ; j++{ jobs <- j fmt.Println("sent job" , j) } close (jobs) fmt.Println("sent all job" ) <-done }
运行结果:
(2)通道数据遍历 通过range语句也可以遍历通道的数据,但是要先关闭掉通道
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func ChannelsRange () queue := make (chan string , 3 ) queue <- "one" queue <- "two" close (queue) for elem := range queue{ fmt.Println(elem) } }
4.select (1)同时响应多个通道的操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 c1 := make (chan string ) c2 := make (chan string ) go func () time.Sleep(1 * time.Second) c1 <- "one" }() go func () time.Sleep(2 * time.Second) c2 <- "two" }() for i := 0 ; i < 2 ; i++{ select { case msg1 := <- c1: fmt.Println(msg1) case msg2 := <- c2: fmt.Println(msg2) } }
运行结果:
(2)非阻塞发送接收 这里所谓的非阻塞是指通过select的default让主线程进入默认分支
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 messages := make (chan string ) signals := make (chan bool ) select { case msg := <-messages: fmt.Println("received message" , msg) default : fmt.Println("no message received" ) } msg := "hi" select { case messages <- msg: fmt.Println("sent message" , msg) default : fmt.Println("no message sent" ) } select { case msg := <- messages: fmt.Println("received message" , msg) case sig := <- signals: fmt.Println("received signal" , sig) default : fmt.Println("no activity" ) }
运行结果:
(3)超时操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func Timeouts () c1 := make (chan string , 1 ) go func () time.Sleep(2 * time.Second) c1 <- "res 1" }() select { case res := <- c1: fmt.Println(res) case <-time.After(1 * time.Second): fmt.Println("timeout 1" ) } }
5.定时器 (1)定时器Timer 定时器的作用与time.Sleep类似,不同的是time.Sleep硬性规定等待一定时间才能继续进程,而定时器可以在触发前取消掉
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 func Timer () time1 := time.NewTimer(2 * time.Second) <- time1.C fmt.Println("Timer 1 fired" ) time2 := time.NewTimer(time.Second) go func () <- time2.C fmt.Println("Time 2 fired" ) }() stop2 := time2.Stop() if stop2 { fmt.Println("Timer 2 stopped" ) } time.Sleep(2 * time.Second) }
运行结果:
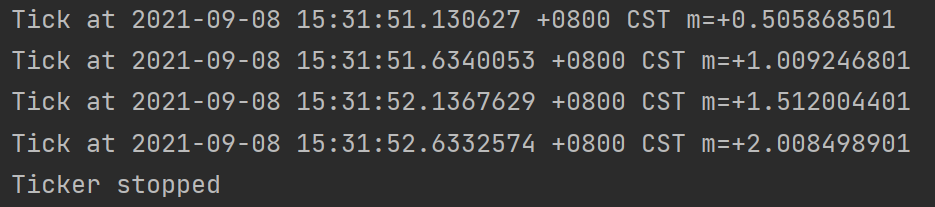
(2)打点器Ticker 定时器用于执行一次时使用,而打点器用于在固定时间间隔重复执行而准备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 func Ticker () ticker := time.NewTicker(500 * time.Millisecond) done := make (chan bool ) go func () for { select { case <- done: return case t := <- ticker.C: fmt.Println("Tick at" , t) } } }() time.Sleep(2000 * time.Millisecond) ticker.Stop() done <- true fmt.Println("Ticker stopped" ) }
运行结果:
(3)速率限制 速率限制是控制服务资源利用和质量的重要机制。 基于协程、通道和打点器,Go 优雅的支持速率限制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 func RateLimiting () requests := make (chan int , 5 ) for i:= 1 ; i <= 5 ; i++{ requests <- i } close (requests) limiter := time.Tick(200 * time.Millisecond) for req := range requests{ <-limiter fmt.Println("request" , req, time.Now()) } burstyLimiter := make (chan time.Time, 3 ) for i := 0 ; i < 3 ; i++{ burstyLimiter <- time.Now() } go func () for t := range time.Tick(200 * time.Millisecond){ burstyLimiter <- t } }() busstyRequests := make (chan int , 5 ) for i := 1 ; i <= 5 ; i++{ busstyRequests <- i } close (busstyRequests) for req := range busstyRequests{ <- burstyLimiter fmt.Println("request" , req, time.Now()) } }
6.Goroutine池 工作池实质上时生产者消费者模型,其可以有效控制gorouine的数量
工作池中有工人(处理工作的协程),有两条流水线(传递工作的通道与传递结果的通道)
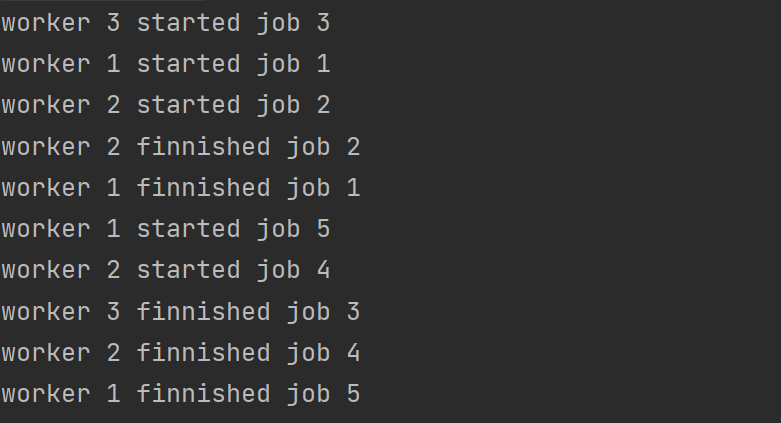
(1)创建工作池 1 2 3 4 5 6 7 8 9 10 11 12 13 func workers (id int , jobs <-chan int , res chan <- int ) for j := range jobs{ fmt.Println("worker" , id, "started job" , j) time.Sleep(time.Second) fmt.Println("worker" , id, "finnished job" , j) res <- j * 2 } }
(2)使用工作池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func WorkerPools () const numJob = 5 jobs := make (chan int , numJob) results := make (chan int , numJob) for w := 1 ; w <= 3 ; w++{ go workers(w, jobs, results) } for j := 1 ; j <= numJob; j++{ jobs <- j } close (jobs) for a := 1 ; a <= numJob; a++{ <-results } }
运行结果:
7.Sync (1)WaitGroup 在前面的例子中
为了同步子协程与主线程我们通过传递done来让主线程等等子协程
为了让主线程等待工作池内的子协程完成任务我们通过收集返回结果来实现同步
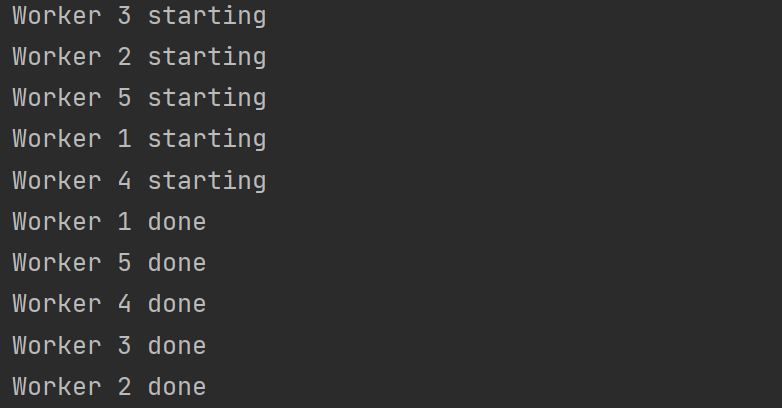
这次我们用 sync.WaitGroup来实现并发任务的同步,其内部维护着一个计数器(每个计数器对应一个并发任务)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 func workerA (id int , wg *sync.WaitGroup) defer wg.Done() fmt.Printf("Worker %d starting\n" , id) time.Sleep(time.Second) fmt.Printf("Worker %d done\n" , id) } func WaitGroup () var wg sync.WaitGroup for i := 1 ; i <= 5 ; i++ { wg.Add(1 ) go workerA(i, &wg) } wg.Wait() }
运行结果:
8.并发安全 在工作池中我们使用通道之间的通信管理状态,下面我们使用atomic原子技术和互斥锁技术管理状态保证并发安全
这里以多协程并发访问同一变量作为并发安全问题的案例
(1)互斥锁 在一个协程操作对资源上锁,其他协程无法访问到该资源,保证了
只有一个协程可以访问共享资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 func Mutexes () var state = make (map [int ]int ) var mutex = &sync.Mutex{} var readOps uint64 var writeOps uint64 for r := 0 ; r < 100 ; r++{ go func () total := 0 for { key := rand.Intn(5 ) mutex.Lock() total += state[key] mutex.Unlock() atomic.AddUint64(&readOps, 1 ) time.Sleep(time.Millisecond) } }() } for w := 0 ; w < 10 ; w++{ go func () key := rand.Intn(5 ) val := rand.Intn(100 ) mutex.Lock() state[key] = val mutex.Unlock() atomic.AddUint64(&writeOps, 1 ) time.Sleep(time.Millisecond) }() } time.Sleep(time.Second) readOpsFinal := atomic.LoadUint64(&readOps) fmt.Println("readOps:" , readOpsFinal) writeOpsFianl := atomic.LoadUint64(&writeOps) fmt.Println("writeOps:" , writeOpsFianl) mutex.Lock() fmt.Println("state:" , state) mutex.Unlock() }
运行结果:
(2)atomic(原子操作) 加锁操作因为涉及内核态的上下文切换会比较耗时、代价比较高。针对基本数据类型我们还可以使用原子操作来保证并发安全
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 func Atomic () var ops uint64 var opn uint64 var wg sync.WaitGroup for i := 0 ; i < 50 ; i++{ wg.Add(1 ) go func () for c := 0 ; c < 1000 ; c++{ atomic.AddUint64(&ops, 1 ) opn++ } wg.Done() }() } wg.Wait() fmt.Println("ops" , ops) fmt.Println("opn" , opn) }
运行结果:
(3)状态协程 互斥锁中通过锁定让state跨多个go协程同步访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 type readOp struct { key int resp chan int } type writeOp struct { key int value int resp chan bool } func SatefulGoroutines () var readOps uint64 var writeOps uint64 reads := make (chan readOp) writes := make (chan writeOp) go func () var state = make (map [int ]int ) for { select { case read := <-reads: read.resp <- state[read.key] case write := <-writes: state[write.key] = write.value write.resp <- true } } }() for r := 0 ; r < 100 ; r++{ go func () for { read := readOp{ key: rand.Intn(5 ), resp: make (chan int ), } reads <- read <- read.resp atomic.AddUint64(&readOps, 1 ) time.Sleep(time.Millisecond) } }() } for w := 0 ; w < 10 ; w++{ go func () for { write := writeOp{ key: rand.Intn(5 ), value: rand.Intn(100 ), resp: make (chan bool ), } writes <- write <- write.resp atomic.AddUint64(&writeOps, 1 ) time.Sleep(time.Millisecond) } }() } time.Sleep(time.Second) readOpsFinal := atomic.LoadUint64(&readOps) fmt.Println("readOps" , readOpsFinal) writeOpsFinal := atomic.LoadUint64(&writeOps) fmt.Println("writeOps" , writeOpsFinal) }
运行结果:
排序 1.自定义排序 这里自定义按字符串长度排序
同过实现go提供的sort.Interface接口来实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 type byLength []string func (s byLength) Len () int return len (s) } func (s byLength) Swap (i, j int ) s[i], s[j] = s[j], s[i] } func (s byLength) Less (i, j int ) bool return len (s[i]) < len (s[j]) } func Sorting () asoul := []string {"Ava" , "Bella" , "Eileen" ,"Carol" , "Diana" } sort.Sort(byLength(asoul)) fmt.Println(asoul) }
运行结果:
JSON 1.基本概念 JSON的编码解码即序列化与反序列化
我们常用byte和string作为数据和json表示形式的中介
编码过程:go的其他数据类型 -> byte(字节数组) -> json
解码过程:json -> byte(字节数组) -> go的其他数据类型(map[string]interface{} / 自定义类型)
2.构造结构体 1 2 3 4 5 6 7 type res struct { Page int Fruits []string }
3.编码 将Go的数据转换为JSON,go的数据在编码后是byte[]类型,所以要转换成string类型才能打印出字符串
(1)map类型编码 1 2 3 4 mapD := map [string ]int {"apple" :5 , "lettuce" :7 } mapB, _ := json.Marshal(mapD) fmt.Println(string (mapB))
运行结果:
(2)自定义类型编码 1 2 3 4 5 6 7 8 9 10 11 res1D := &res{ Page: 1 , Fruits: []string {"apple" , "peach" , "pear" }, } res1B, _ := json.Marshal(res1D) fmt.Println(string (res1B))
运行结果:
4.解码 将JSON转换为Go语言可以读取的数据类型,
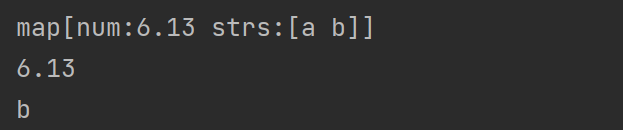
(1)map类型接收 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 byt := []byte (`{"num":6.13, "strs":["a", "b"]}` ) var dat map [string ]interface {}if err := json.Unmarshal(byt, &dat); err != nil { panic (err) } fmt.Println(dat) num := dat["num" ].(float64 ) fmt.Println(num) strs := dat["strs" ].([]interface {}) str1 := strs[1 ].(string ) fmt.Println(str1)
运行结果:
(2)自定义数据类型接收 1 2 3 4 5 6 7 8 9 10 str := `{"page": 1, "fruits": ["apple", "peach"]}` fmt.Println(reflect.TypeOf(str)) res := res{} json.Unmarshal([]byte (str), &res) fmt.Println(res) fmt.Println(res.Fruits[0 ])
运行结果:
(3)Encode接收 1 2 3 4 5 6 enc := json.NewEncoder(os.Stdout) d := map [string ]int {"apple" : 5 , "lettuce" : 7 } enc.Encode(d)
运行结果:
单元测试 1.单元测试命名规则
文件名必须以xx_test.go命名
方法必须是Test开头
方法参数必须 t *testing.T
测试例与被测试对象要放在一个包中
使用go test执行单元测试(idea可以直接运行测试例)
2.被测对象 1 2 3 4 5 6 7 8 9 func IntMin (a, b int ) int if a < b{ return a } else { return b } }
3.一般测试例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func TestIntMinBasic (t *testing.T) ans := IntMin(2 , -2 ) if ans != -2 { t.Errorf("IntMin(2, -2) = %d; want -2" , ans) } else { fmt.Println(ans) } }
4.表驱动测试例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func TestIntMinTableDriven (t *testing.T) var tests = []struct { a, b int want int }{ {0 , 1 , 0 }, {1 , 0 , 0 }, {2 , -2 , -2 }, {0 , -1 , -1 }, {-1 , 0 , -1 }, } for _, tt := range tests { testname := fmt.Sprintf("%d, %d" , tt.a, tt.b) t.Run(testname, func (t *testing.T) ans := IntMin(tt.a, tt.b) if ans != tt.want{ t.Errorf("got %d, want %d" , ans, tt.want) } }) }
HTTP客户端 1.GET请求 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 resp1, err := http.Get("https://search.bilibili.com/" ) if err != nil { panic (err) } defer resp1.Body.Close()fmt.Println(resp1) fmt.Println("Response status" , resp1.Status) body, err := ioutil.ReadAll(resp1.Body) if err != nil { fmt.Println(err) } fmt.Println(string (body))
2.带参数GET请求 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 apiurl := "https://search.bilibili.com/all" data := url.Values{} data.Set("keyword" , "Autovy" ) data.Set("from_source" , "webtop_search" ) u, err := url.ParseRequestURI(apiurl) if err != nil { fmt.Println(err) } u.RawQuery = data.Encode() fmt.Println(u.String()) resp2, err := http.Get(u.String()) if err != nil { fmt.Println("post failed, err:%v\n" , err) return } defer resp2.Body.Close()b, err := ioutil.ReadAll(resp2.Body) if err != nil { fmt.Println("get resp failed,err:%v\n" , err) return } fmt.Println(string (b))
3.POST请求 (1)发送from-data 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 data2 := url.Values{ "name" : {"Autovy" }, "occupation" : {"programmar" }, } resp, err := http.PostForm("https://httpbin.org/post" , data2) if err != nil { panic (err) } var res map [string ]interface {}json.NewDecoder(resp.Body).Decode(&res) fmt.Println(res["form" ])
运行结果:
(2)发送json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 values := map [string ]string {"name" : "Ava" , "occupation" : "Gamer" } json_data, err := json.Marshal(values) if err != nil { panic (err) } resp3, err := http.Post("https://httpbin.org/post" , "application/json" , bytes.NewBuffer(json_data)) if err != nil { panic (err) } var res2 map [string ]interface {}json.NewDecoder(resp3.Body).Decode(&res2) fmt.Println(res2["json" ])
运行结果:
HTTP服务端 服务端构造处理请求的函数handler
handler 函数有两个参数,http.ResponseWriter 和 http.Request
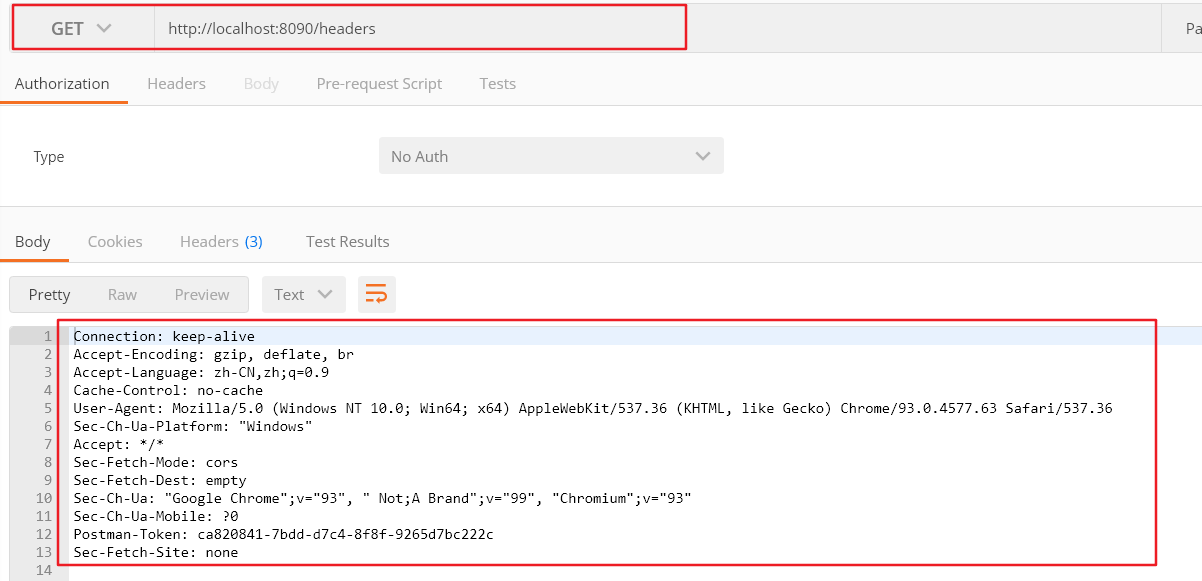
1.普通服务 (1)处理http请求 1 2 3 4 5 6 7 8 9 func headers (w http.ResponseWriter, req *http.Request) for name, headers := range req.Header { for _, h := range headers { fmt.Fprintf(w, "%v: %v\n" , name, h) } } }
(2)函数注册到路由 1 2 3 4 http.HandleFunc("/headers" , headers) http.ListenAndServe(":8090" , nil )
运行结果:
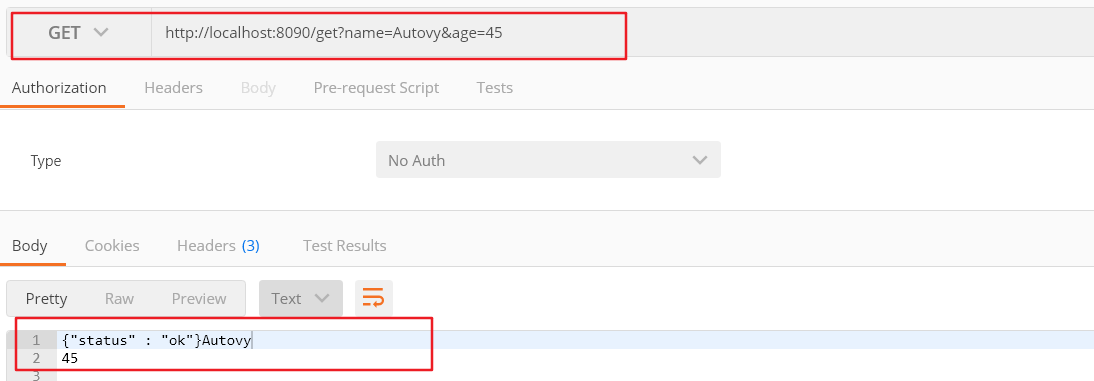
2.接受GET请求参数 (1)处理get请求 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func getHandler (w http.ResponseWriter, r *http.Request) defer r.Body.Close() data := r.URL.Query() answer := `{"status" : "ok"}` w.Write([]byte (answer)) fmt.Fprintln( w ,data.Get("name" )) fmt.Fprintln( w ,data.Get("age" )) }
(2)函数注册到路由 1 2 3 4 http.HandleFunc("/get" , getHandler) http.ListenAndServe(":8090" , nil )
运行结果:
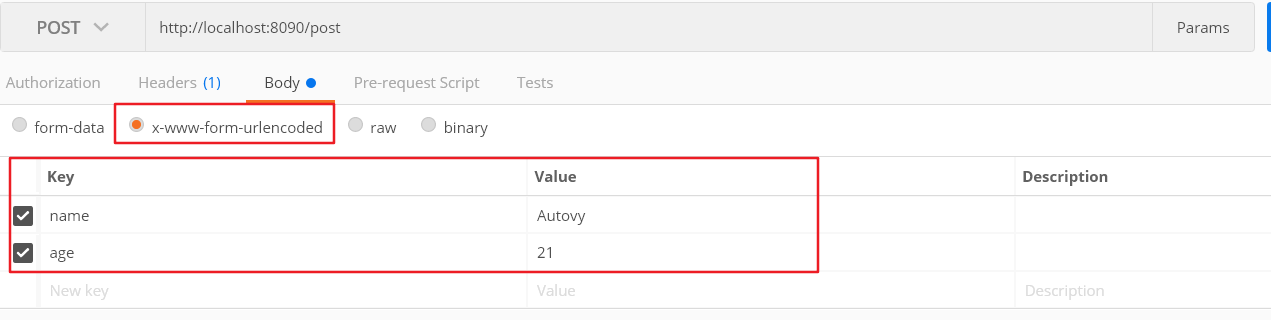
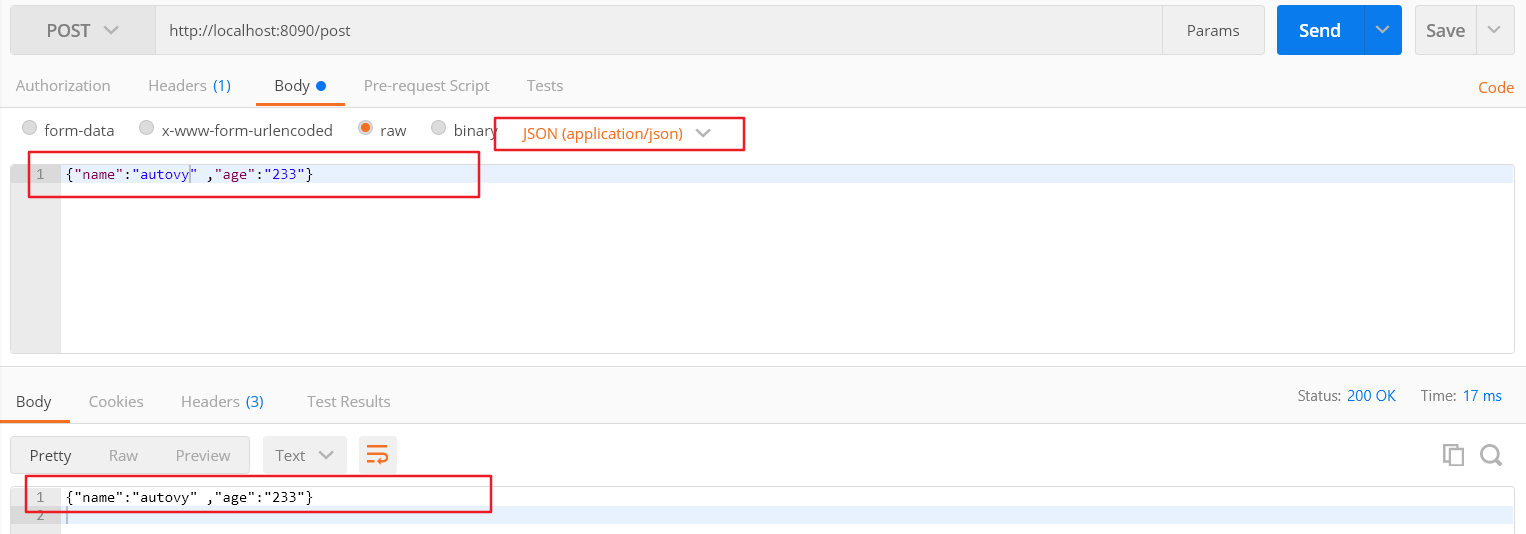
3.接受POST请求参数 (1)处理post请求函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func postHandler (w http.ResponseWriter, r *http.Request) defer r.Body.Close() r.ParseForm() fmt.Println(r.PostForm) fmt.Println(r.PostForm.Get("name" ), r.PostForm.Get("age" )) b, err := ioutil.ReadAll(r.Body) if err != nil { fmt.Println(err) return } fmt.Fprintln(w, string (b)) }
(2)函数注册到路由 1 2 3 4 http.HandleFunc("/post" , postHandler) http.ListenAndServe(":8090" , nil )
运行结果:
(3)请求类型为application/json 服务端可以进行反序列化操作得到json内的数据
结束
快乐生活,快乐工作,快乐学习
os.Exit(1)