数据库架构 数据库结构图
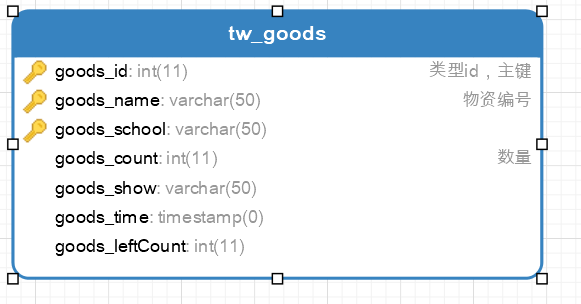
主要数据表信息 一.物资申请表
用户id : 物资申请条目 = 1 : n
机构id : 物资申请条目 = 1 : n
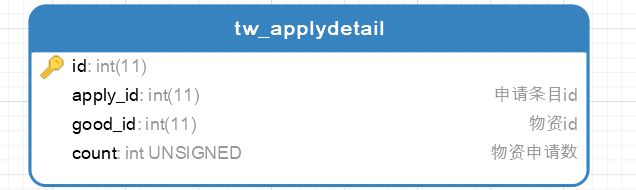
二.物资申请详情表
物资申请条目id : 物资申请详情条目 = n : n
物资id : 物资申请详情条目 = n : n
(物资申请条目id,物资id) : 物资申请详情条目 = 1 : n
三.物资表
四.用户表
五.权限表
系统架构 技术架构 一.前端
Vue.js:前端逻辑处理数据
Bootstrap:使用模板样式
Jquery
axios
Thymeleaf:主要使用其HTML包含技术,整合页面共用部分(Springboot官方推荐的视图)
二.后端
SpringBoot 1.5.9 RELEASE
Shiro安全框架
Maven
Hibernate
Elasticsearch搜索引擎
三.数据库
相关依赖准备 pom.xml文件导入相关依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-tomcat</artifactId > <scope > provided</scope > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-devtools</artifactId > <optional > true</optional > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-jpa</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-redis</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-thymeleaf</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-elasticsearch</artifactId > </dependency > <dependency > <groupId > com.sun.jna</groupId > <artifactId > jna</artifactId > <version > 3.0.9</version > </dependency > <dependency > <groupId > net.sourceforge.nekohtml</groupId > <artifactId > nekohtml</artifactId > <version > 1.9.22</version > </dependency > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.12</version > <scope > test</scope > </dependency > <dependency > <groupId > org.apache.tomcat.embed</groupId > <artifactId > tomcat-embed-jasper</artifactId > <version > 8.5.23</version > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 5.1.21</version > </dependency > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.12</version > </dependency > <dependency > <groupId > commons-lang</groupId > <artifactId > commons-lang</artifactId > <version > 2.6</version > </dependency > <dependency > <groupId > org.apache.shiro</groupId > <artifactId > shiro-spring</artifactId > <version > 1.3.2</version > </dependency > <dependency > <groupId > org.hsqldb</groupId > <artifactId > hsqldb</artifactId > </dependency > <dependency > <groupId > com.google.guava</groupId > <artifactId > guava</artifactId > <version > 20.0</version > </dependency > <dependency > <groupId > io.springfox</groupId > <artifactId > springfox-swagger2</artifactId > <version > 2.9.2</version > </dependency > <dependency > <groupId > com.github.xiaoymin</groupId > <artifactId > swagger-bootstrap-ui</artifactId > <version > 1.9.6</version > </dependency > </dependencies >
开发内容 MySQL优化过程 一.T-SQL脚本分表优化 1.相关表的结构 此处展示的表结构为维护前
物资申请表:共4817条数据
物资信息表:
goods_count:当前仓库物品数(物理的)
good_leftCount:当前物品可借数(网络的:存在部分未借出,但已被预订仍在审核中的物品)
2.优化思路:物资申请表分表 从上面的tw_apply表就可以知道:
还好后端大哥没有把物资申请信息的字符串直接发给前端,我真的哭死,设计数据库的那个出来挨打(前端不需要解析,但是要拼接展示字符串)
数据库设计十分不合理,甚至不符合第一范式,浪费数据库大量存储空间 不说,而且后端拼接字符串解析字符串这一过程十分耗时且占用内存 ,而且最新的需求是需要增加一个审核过程申请物资调整功能
所以我将物资申请表进行分表(水平分表),分出物资申请详情表并联系物资信息表,其结构如下
删除掉apply_content字段,节省数据库空间
分表后,通过tw_applydetail表,我们对物资申请信息的所以内容进行操作,省去了物资审核接口对字符串解析的耗时过程并且方便审核过程申请物资调整功能的开发(通过tw_appdetail找到物品信息和物品数量)
3.优化操作:存储过程脚本 存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象
这里值得注意的是在遍历游标的循环中,如果查询不存在或为空会跳出循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 CREATE DEFINER= `Autovy`@`localhost` PROCEDURE `demo`()BEGIN DECLARE i INT DEFAULT 0 ;DECLARE s int DEFAULT 0 ;DECLARE n TINYTEXT;DECLARE m INT (11 ); # 求分割符号',' 的位置 DECLARE _index INT ;# 单个物品申请信息 DECLARE str TINYTEXT;# 单个物品申请信息长度 DECLARE strLength int ;# 物品名称 DECLARE goodName VARCHAR (10 );# 物品数量 DECLARE goodCount int (11 );# 物品id DECLARE goodId int (11 );DECLARE apply_id1 CURSOR FOR SELECT id, apply_content FROM tw_apply WHERE apply_content LIKE "本部%";DECLARE CONTINUE HANDLER FOR NOT FOUND SET s= 1 ;OPEN apply_id1;FETCH apply_id1 into m, n;while s<> 1 do SET _index = LOCATE(';' , n); while _index > 0 do SET str = LEFT (n, _index-1 ); SET strLength = LENGTH(str) / 5 ; SET goodName = LEFT (str, strLength); SET goodCount = CAST (LEFT (RIGHT (str, 2 ), 1 ) AS signed) ; SELECT goodName; SELECT goods_id into goodId FROM tw_goods WHERE goods_show LIKE goodName ORDER BY goods_count DESC LIMIT 1 ; INSERT tw_applydetail(apply_id, good_id, count) VALUES (m, goodId, goodCount); SET n = SUBSTR(n FROM _index+ 1 ); SET _index = LOCATE(';' , n); end while; set i = i+ 1 ; FETCH apply_id1 into m, n;end while;close apply_id1; END
当时经过一天的对存储过程的学习,我总结出了以下经验:存储过程非常不方便调试,而且报错信息只定位不报错误类型(sql是这样的)。如果能重来,对数据库的批量操作,首选Python或Shell
4.优化结果
截至目前物资申请表已有4817条数据,考虑到后面数据会长期积累,这样的优化是有必要的
去掉后端耗时耗内存的字符串解析工作
节省数据库存储空间,优化前申请表内存占0.79MB,优化后占0.56MB
另外附加一个容量查询小工具,可查询数据库各表容量大小
1 2 3 4 5 6 7 8 9 select table_schema as '数据库', table_name as '表名', table_rows as '记录数', truncate(data_length/1024/1024, 2) as '数据容量(MB)', truncate(index_length/1024/1024, 2) as '索引容量(MB)' from information_schema.tables where table_schema='bgs' order by data_length desc, index_length desc;
二.索引优化查询 1.相关表结构 日志记录表:共33687条数据
2.优化思路:添加索引 关于索引的知识点这里不细说,推荐阅读:MySQL 索引详解
由于日志表数据庞大,有3万条数据,为了达到快速通过用户名模糊查找到日志操作内容和操作时间,就需要用到索引,另外在模糊查询中,like语句要使索引生效,like后不能以%开始,也就是说 (like %字段名%) 、(like %字段名)这类语句会使索引失效,而(like 字段名)、(like 字段名%)这类语句索引是可以正常使用
所以我将查询的模糊匹配由“%xxxx%”改为“xxxx%”,只模糊匹配前面部分
3.优化操作 这里直接使用Navicat可视化添加索引,因为后台查询日志是需要用用户名模糊查找到日志操作内容和操作时间,所以需要添加的索引为log_realnam
更改mybatis的sql映射,解决sql注入和索引失效问题
1 SELECT log_realname, log_content, log_time FROM tw_log WHERE log_realname LIKE "%${log_name}%";
在这种情况下使用#程序会报错,新手程序员就把#号改成了$,这样如果java代码层面没有对用户输入的内容做处理势必会产生SQL注入漏洞。
正确写法:
1 SELECT log_realname, log_content, log_time FROM tw_log WHERE log_realname LIKE concat(‘%’,#{log_name}, ‘%’)
4.优化结果
添加索引前使用用户名模糊查询日志,耗时大约0.045s,添加索引后耗时大约0.032s,减少了磁盘IO,提高了查询速度
修改mybatis中模糊查询的sql语句,解决索引失效的问题,并解决了模糊查询中拼接字符串的sql注入问题
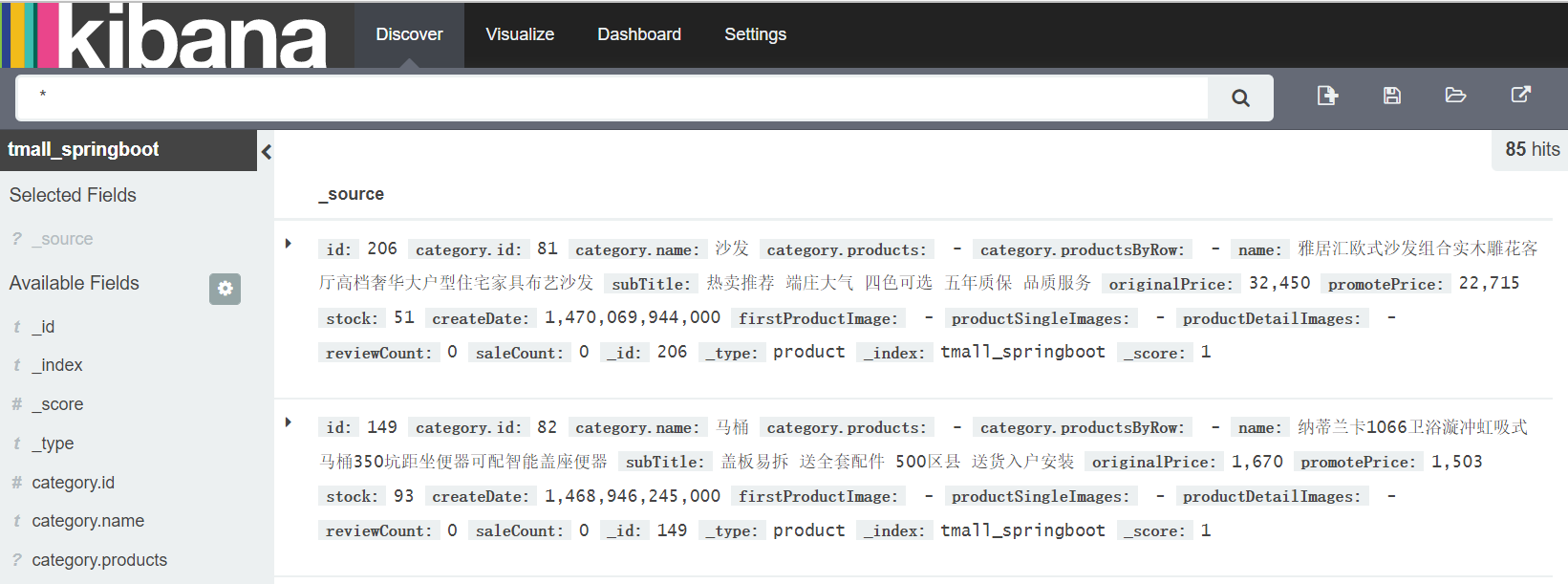
Elasticsearch搜索 一.ES配置 1.ES可视化 kibana是es的可视化工具,开启后可以通过访问 http://127.0.0.1:5601/ 查看kibana页面
2.配置ES 1 2 spring.data.elasticsearch.cluster-nodes = 127.0.0.1:9300
二.ES开发流程 1.ES注解实体类 1 2 3 @Document(indexName = "tmall_springboot",type = "product")
2.esDAO的创建 由于整合了ES的JPA和操作数据库使用的JPA有冲突,所以不能放在同一个包下
1 2 3 4 5 6 7 8 9 10 11 12 package com.how2java.tmall.es;import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;import com.how2java.tmall.pojo.Product;public interface ProductESDAO extends ElasticsearchRepository <Product ,Integer >}
3.Application引入ES 1 2 3 4 5 @EnableElasticsearchRepositories(basePackages = "com.how2java.tmall.es") @EnableJpaRepositories(basePackages = {"com.how2java.tmall.dao", "com.how2java.tmall.pojo"})
4.服务层同步ES 增删改操作
增删改操作的数据需要同步ES和数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @CacheEvict(allEntries=true) public void add (Product bean) productDAO.save(bean); productESDAO.save(bean); } @CacheEvict(allEntries=true) public void delete (int id) productDAO.delete(id); productESDAO.delete(id); } @CacheEvict(allEntries=true) public void update (Product bean) productDAO.save(bean); productESDAO.save(bean); }
ES初始化
ES内数据为空,就将数据库中的数据同步到es
1 2 3 4 5 6 7 8 9 10 11 12 13 private void initDatabase2ES () Pageable pageable = new PageRequest(0 , 5 ); Page<Product> page =productESDAO.findAll(pageable); if (page.getContent().isEmpty()) { List<Product> products= productDAO.findAll(); for (Product product : products) { productESDAO.save(product); } } }
5.服务层查询ES 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public List<Product> search (String keyword, int start, int size) initDatabase2ES(); FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery() .add(QueryBuilders.matchPhraseQuery("name" , keyword), ScoreFunctionBuilders.weightFactorFunction(100 )) .scoreMode("sum" ) .setMinScore(10 ); Sort sort = new Sort(Sort.Direction.DESC,"id" ); Pageable pageable = new PageRequest(start, size,sort); SearchQuery searchQuery = new NativeSearchQueryBuilder() .withPageable(pageable) .withQuery(functionScoreQueryBuilder).build(); Page<Product> page = productESDAO.search(searchQuery); return page.getContent(); }
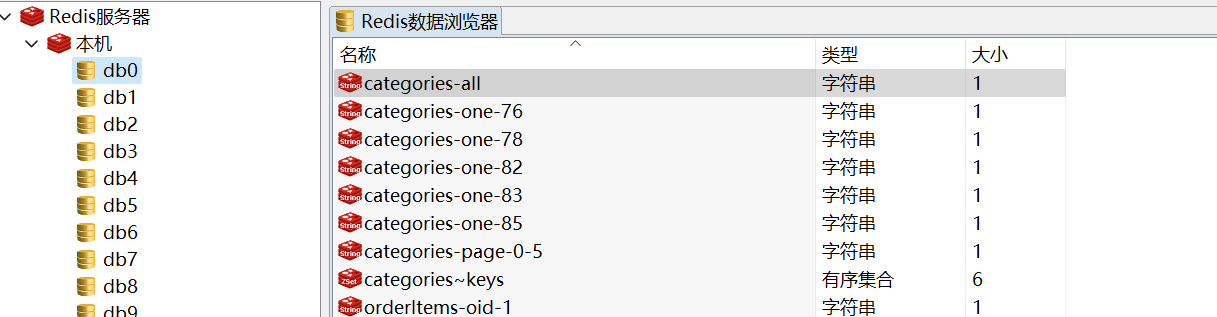
Redis缓存 一.Redis可视化工具 推荐使用RedisClient,数据一般都在db0中
二.Redis配置 1.Redis配置类 该缓存配置类主要是使redis内的key和value转换为可读性的字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Configuration public class RedisConfig extends CachingConfigurerSupport @Bean public CacheManager cacheManager (RedisTemplate<?,?> redisTemplate) RedisSerializer stringSerializer = new StringRedisSerializer(); Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.PUBLIC_ONLY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); redisTemplate.setKeySerializer(stringSerializer); redisTemplate.setHashKeySerializer(stringSerializer); redisTemplate.setValueSerializer(jackson2JsonRedisSerializer); redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer); CacheManager cacheManager = new RedisCacheManager(redisTemplate); return cacheManager; } }
2.Redis配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 spring.redis.database =0 spring.redis.host =127.0.0.1 spring.redis.port =6379 spring.redis.password =spring.redis.pool.max-active =10 spring.redis.pool.max-wait =-1 spring.redis.pool.max-idle =8 spring.redis.pool.min-idle =0 spring.redis.timeout =0
三.缓存启用与检测 1.缓存的启用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @SpringBootApplication @EnableCaching @EnableElasticsearchRepositories(basePackages = "com.how2java.tmall.es") @EnableJpaRepositories(basePackages = {"com.how2java.tmall.dao", "com.how2java.tmall.pojo"}) public class Application static { PortUtil.checkPort(6379 ,"Redis 服务端" ,true ); PortUtil.checkPort(9300 ,"ElasticSearch 服务端" ,true ); PortUtil.checkPort(5601 ,"Kibana 工具" , true ); } public static void main (String[] args) SpringApplication.run(Application.class, args); } }
2.服务开启检测 这里的PortUtil是一个检测端口上服务是否运行的简单工具类,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package com.how2java.tmall.util;import java.io.IOException;import java.net.ServerSocket;import javax.swing.JOptionPane;public class PortUtil public static boolean testPort (int port) try { ServerSocket ss = new ServerSocket(port); ss.close(); return false ; } catch (java.net.BindException e) { return true ; } catch (IOException e) { return true ; } } public static void checkPort (int port, String server, boolean shutdown) if (!testPort(port)) { if (shutdown) { String message =String.format("在端口 %d 未检查得到 %s 启动%n" ,port,server); JOptionPane.showMessageDialog(null , message); System.exit(1 ); } else { String message =String.format("在端口 %d 未检查得到 %s 启动%n,是否继续?" ,port,server); if (JOptionPane.OK_OPTION != JOptionPane.showConfirmDialog(null , message)) System.exit(1 ); } } } }
四.缓存的使用 缓存的使用一般在服务层使用
1.有序集合管理 通过在服务层中注解@CacheConfig,创建一个有序集合类型的缓存,管理该服务下所有的keys
1 2 3 4 5 6 7 8 @Service @CacheConfig(cacheNames="categories") public class CategoryService ..... }
2查询插入缓存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Cacheable(key="'categories-one-'+ #p0") public Category get (int id) Category c= categoryDAO.findOne(id); return c; } @Cacheable(key="'categories-page-'+#p0+ '-' + #p1") public Page4Navigator<Category> list (int start, int size, int navigatePages) Sort sort = new Sort(Sort.Direction.DESC, "id" ); Pageable pageable = new PageRequest(start, size, sort); Page pageFromJPA =categoryDAO.findAll(pageable); return new Page4Navigator<>(pageFromJPA,navigatePages); }
返回的java对象或集合都会变成JSON字符串
3.更新删除缓存 准确来说是插入,删除,更新删除缓存以保持数据一致性
使用@CacheEvict(allEntries=true)删除category~keys的所有keys
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @CacheEvict(allEntries=true) public void add (Category bean) categoryDAO.save(bean); } @CacheEvict(allEntries=true) public void delete (int id) categoryDAO.delete(id); } @CacheEvict(allEntries=true) public void update (Category bean) categoryDAO.save(bean); }
Shiro登录验证 由于本项目仅仅有用户一个权限,所以只需要判断用户是否登录,并不需要比较细粒度的权限分配
一.JPARealm验证授权器 Shiro与用户之间的中介,为Shiro提供验证和授权用户的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.how2java.tmall.realm;import org.apache.shiro.authc.AuthenticationException;import org.apache.shiro.authc.AuthenticationInfo;import org.apache.shiro.authc.AuthenticationToken;import org.apache.shiro.authc.SimpleAuthenticationInfo;import org.apache.shiro.authz.AuthorizationInfo;import org.apache.shiro.authz.SimpleAuthorizationInfo;import org.apache.shiro.realm.AuthorizingRealm;import org.apache.shiro.subject.PrincipalCollection;import org.apache.shiro.util.ByteSource;import org.springframework.beans.factory.annotation.Autowired;import com.how2java.tmall.pojo.User;import com.how2java.tmall.service.UserService;public class JPARealm extends AuthorizingRealm @Autowired private UserService userService; @Override protected AuthenticationInfo doGetAuthenticationInfo (AuthenticationToken token) throws AuthenticationException String userName = token.getPrincipal().toString(); User user = userService.getByName(userName); String passwordInDB = user.getPassword(); String salt = user.getSalt(); SimpleAuthenticationInfo authenticationInfo = new SimpleAuthenticationInfo(userName, passwordInDB, ByteSource.Util.bytes(salt), getName()); return authenticationInfo; } @Override protected AuthorizationInfo doGetAuthorizationInfo (PrincipalCollection principalCollection) SimpleAuthorizationInfo s = new SimpleAuthorizationInfo(); return s; } }
二.Shiro配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 package com.how2java.tmall.config;import com.how2java.tmall.realm.JPARealm;import org.apache.shiro.authc.credential.HashedCredentialsMatcher;import org.apache.shiro.mgt.SecurityManager;import org.apache.shiro.spring.LifecycleBeanPostProcessor;import org.apache.shiro.spring.security.interceptor.AuthorizationAttributeSourceAdvisor;import org.apache.shiro.spring.web.ShiroFilterFactoryBean;import org.apache.shiro.web.mgt.DefaultWebSecurityManager;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configuration public class ShiroConfiguration @Bean public static LifecycleBeanPostProcessor getLifecycleBeanPostProcessor () return new LifecycleBeanPostProcessor(); } @Bean public ShiroFilterFactoryBean shirFilter (SecurityManager securityManager) ShiroFilterFactoryBean shiroFilterFactoryBean = new ShiroFilterFactoryBean(); shiroFilterFactoryBean.setSecurityManager(securityManager); return shiroFilterFactoryBean; } @Bean public SecurityManager securityManager () DefaultWebSecurityManager securityManager = new DefaultWebSecurityManager(); securityManager.setRealm(getJPARealm()); return securityManager; } @Bean public JPARealm getJPARealm () JPARealm myShiroRealm = new JPARealm(); myShiroRealm.setCredentialsMatcher(hashedCredentialsMatcher()); return myShiroRealm; } @Bean public HashedCredentialsMatcher hashedCredentialsMatcher () HashedCredentialsMatcher hashedCredentialsMatcher = new HashedCredentialsMatcher(); hashedCredentialsMatcher.setHashAlgorithmName("md5" ); hashedCredentialsMatcher.setHashIterations(2 ); return hashedCredentialsMatcher; } @Bean public AuthorizationAttributeSourceAdvisor authorizationAttributeSourceAdvisor (SecurityManager securityManager) AuthorizationAttributeSourceAdvisor authorizationAttributeSourceAdvisor = new AuthorizationAttributeSourceAdvisor(); authorizationAttributeSourceAdvisor.setSecurityManager(securityManager); return authorizationAttributeSourceAdvisor; } }
三.注册接口 Realm的验证需要对应注册里的加密方法即md5 * 2 + 盐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @PostMapping("/foreregister") public Object register (@RequestBody User user) String name = user.getName(); String password = user.getPassword(); name = HtmlUtils.htmlEscape(name); user.setName(name); boolean exist = userService.isExist(name); if (exist){ String message ="用户名已经被使用,不能使用" ; return Result.fail(message); } String salt = new SecureRandomNumberGenerator().nextBytes().toString(); int times = 2 ; String algorithmName = "md5" ; String encodedPassword = new SimpleHash(algorithmName, password, salt, times).toString(); user.setSalt(salt); user.setPassword(encodedPassword); userService.add(user); return Result.success(); }
四.登录接口 配置好Shiro后,登录验证时可以快速使用啦!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @PostMapping("/forelogin") public Object login (@RequestBody User userParam, HttpSession session) String name = userParam.getName(); name = HtmlUtils.htmlEscape(name); Subject subject = SecurityUtils.getSubject(); UsernamePasswordToken token = new UsernamePasswordToken(name, userParam.getPassword()); try { subject.login(token); User user = userService.getByName(name); session.setAttribute("user" , user); return Result.success(); } catch (AuthenticationException e) { String message ="账号密码错误" ; return Result.fail(message); } }
拦截器 拦截前端某些没有权限的访问,如没有登录权限的用户访问个人信息表,跳转到登录页
一.拦截器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 package com.how2java.tmall.interceptor;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import javax.servlet.http.HttpSession;import org.apache.commons.lang.StringUtils;import org.apache.shiro.SecurityUtils;import org.apache.shiro.subject.Subject;import org.springframework.web.servlet.HandlerInterceptor;import org.springframework.web.servlet.ModelAndView;public class LoginInterceptor implements HandlerInterceptor @Override public boolean preHandle (HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o) throws Exception HttpSession session = httpServletRequest.getSession(); String contextPath=session.getServletContext().getContextPath(); String[] requireAuthPages = new String[]{ "buy" , "alipay" , "payed" , "cart" , "bought" , "confirmPay" , "orderConfirmed" , "forebuyone" , "forebuy" , "foreaddCart" , "forecart" , "forechangeOrderItem" , "foredeleteOrderItem" , "forecreateOrder" , "forepayed" , "forebought" , "foreconfirmPay" , "foreorderConfirmed" , "foredeleteOrder" , "forereview" , "foredoreview" }; String uri = httpServletRequest.getRequestURI(); uri = StringUtils.remove(uri, contextPath+"/" ); String page = uri; if (begingWith(page, requireAuthPages)){ Subject subject = SecurityUtils.getSubject(); if (!subject.isAuthenticated()) { httpServletResponse.sendRedirect("login" ); return false ; } } return true ; } private boolean begingWith (String page, String[] requiredAuthPages) boolean result = false ; for (String requiredAuthPage : requiredAuthPages) { if (StringUtils.startsWith(page, requiredAuthPage)) { result = true ; break ; } } return result; } @Override public void postHandle (HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, ModelAndView modelAndView) throws Exception } @Override public void afterCompletion (HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Object o, Exception e) throws Exception } }
通过实现SpringMCV的HandlerInterceptor来实现拦截器,其中包含3个方法:
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handle)
该方法将在请求处理之前进行调用。SpringMVC中的Interceptor是链式的调用的,在一个应用中或者说是在一个请求中可以同时存在多个Interceptor 。
每个Interceptor的调用会依据它的声明顺序依次执行,而且最先执行的都是Interceptor中的preHandle方法,所以可以在这个方法中进行一些前置初始化操作或者是对当前请求的一个预处理,也可以在这个方法中进行一些判断来决定请求是否要继续进行下去。
该方法的返回值是布尔值Boolean类型的,当它返回为false 时,表示请求结束,后续的Interceptor和Controller都不会再执行;
当返回值为true时就会继续调用下一个Interceptor的preHandle方法,如果已经是最后一个Interceptor的时候就会是调用当前请求的Controller方法
postHandle(HttpServletRequest request, HttpServletResponse response, Object handle, ModelAndView modelAndView)
postHandle方法,顾名思义就是在当前请求进行处理之后,也就是Controller方法调用之后执行,
postHandle方法被调用的方向跟preHandle是相反的,也就是说先声明的Interceptor 的postHandle方法反而会后执行,这和Struts2里面的Interceptor 的执行过程有点类型。Struts2 里面的Interceptor 的执行过程也是链式的,只是在Struts2 里面需要手动调用ActionInvocation 的invoke 方法来触发对下一个Interceptor 或者是Action 的调用,然后每一个Interceptor 中在invoke 方法调用之前的内容都是按照声明顺序执行的,而invoke 方法之后的内容就是反向的
afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handle, Exception ex)
顾名思义,该方法将在整个请求结束之后,也就是在DispatcherServlet 渲染了对应的视图之后执行。
二.拦截器配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.how2java.tmall.config;import com.how2java.tmall.interceptor.LoginInterceptor;import com.how2java.tmall.interceptor.OtherInterceptor;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.web.servlet.config.annotation.InterceptorRegistry;import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter;@Configuration class WebMvcConfigurer extends WebMvcConfigurerAdapter @Bean public LoginInterceptor getLoginIntercepter () return new LoginInterceptor(); } }
技术亮点 循环依赖解决方案 一.Springboot注解补充 实体类中,@Transient注解的字段,是不与数据库映射的,可以额外添加到接口的字段即该字段不参与自动关联中的sql查询
这些字段可以用来存储:通过查询数据库得到的列表(不用另外建集合对象存储),需要经过计算的数据(也可以放在数据库),数据状态(也可以放在数据库)
订单表@Transient注解字段,在服务层进行赋值操作
1 2 3 4 5 6 7 8 9 10 11 12 @Transient private List<OrderItem> orderItems;@Transient private float total;@Transient private int totalNumber;@Transient private String statusDesc;
使用
@ManyToOne
可以标注关系,就可以使用JPA的findBy等方法如:findByProductOrderByIdDesc
1 2 3 4 5 6 7 8 9 @ManyToOne @JoinColumn(name="pid") private Product product;@ManyToOne @JoinColumn(name="ptid") private Property property;
二.数据库设计:多对多关系 在实际应用中,多对多关系会分解为两个一对多的关系
属性值由产品和属性共同决定
1 2 3 4 5 6 7 8 9 @ManyToOne @JoinColumn(name="pid") private Product product;@ManyToOne @JoinColumn(name="ptid") private Property property;
订单项由订单,用户,产品共同决定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @ManyToOne @JoinColumn(name="pid") private Product product;@ManyToOne @JoinColumn(name="oid") private Order order;@ManyToOne @JoinColumn(name="uid") private User user;
在review类中的内对象如:prouct,user由于一对多的关联,在数据库中映射为pid,uid字段)
所以说JPA是一个ORM框架,对象和数据库无缝衔接
三.循环依赖的解决 在SpringBoot + JPA的架构中,容易出现循环依赖问题,一般会出现在一对多的场景下,总结来说是一对多实体中都要引用对方来维持OnetoMany的关系,所以极容易出现循环依赖:(
1.经典场景 订单项中引用订单,以构成多对一关系
可以使用订单项查找其属于的订单
1 2 3 4 @ManyToOne @JoinColumn(name="oid") private Order order;
订单中引用订单项存储在集合中,用来存储从数据库查询来的结构(往往是因为要利用这些字段进行计算)
可以使用订单id查找订单项列表
1 2 3 4 5 6 7 8 9 @Transient private List<OrderItem> orderItems;@Transient private float total;@Transient private int totalNumber;
这样的结构就是循环依赖,导致数据重复加载,因为orderItems要调用方法填充,所以会为空(一般情况下会栈溢出)最终造成的数据是:Order含有orderItems,orderItems含有Order,Order的orderItem列表为空,所以这里的Order重复了一次
2.方案一:@JsonBackReference注解 JsonBackReference注解用在一(一对多的一)的一方,可以阻止其被序列化,前提是对应的接口不需要调用到它,而只是需要用它来查询
如:一个产品有多张图片,我们不需要在图片列表接口使用到产品信息,而只是需要用产品id查询其图片
产品类
1 2 3 4 5 6 7 @Transient private ProductImage firstProductImage;@Transient private List<ProductImage> productSingleImages;@Transient private List<ProductImage> productDetailImages;
产品图片类
1 2 3 4 @ManyToOne @JoinColumn(name="pid") @JsonBackReference private Product product;
缺点
关系是双向的,使用了JsonBackReference,就无法使用根据图片找到其属于的产品的方法,只能单方向查询即根据产品查找到其图片列表
JsonBackReference标记的字段与Redis的整合会有冲突
3.方案二:及时清除法 在服务层定义清除方法,在控制层调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void removeOrderFromOrderItem (List <Order> orders) for (Order order : orders) { removeOrderFromOrderItem(order); } } public void removeOrderFromOrderItem (Order order) List<OrderItem> orderItems= order.getOrderItems(); for (OrderItem orderItem : orderItems) { orderItem.setOrder(null ); } }
1 2 3 4 orderItemService.fill(page.getContent()); orderService.removeOrderFromOrderItem(page.getContent());
4.方案三:延迟加载 关于延迟加载:延迟加载介绍
使用FetchType.LAZY的方法,在不适用关系属性时,就不会自动获取,而一旦触发使用就会自动获取其属性 问题是Jackson对Hibernate的LazyFetch并不默认支持,需要一些额外支持
使用jackson-datatype-hibernate5插件使Jackson支持hibernate的lazyFetch
pom.xml中添加依赖
1 2 3 4 5 <dependency > <groupId > com.fasterxml.jackson.datatype</groupId > <artifactId > jackson-datatype-hibernate5</artifactId > <version > 2.10.1</version > </dependency >
增加配置类
1 2 3 4 5 6 7 8 9 10 11 @Configuration public class HibernateModuleConfig @Bean public MappingJackson2HttpMessageConverter mappingJackson2HttpMessageConverter () MappingJackson2HttpMessageConverter jsonConverter = new MappingJackson2HttpMessageConverter(); ObjectMapper objectMapper = jsonConverter.getObjectMapper(); objectMapper.registerModule(new Hibernate5Module()); return jsonConverter; } }
实体上增加主键Id识别信息,防止出现循环引用 所有关系都为Lazy,直观上不会出现循环引用,但是当你通过一对多查询而多对一存在引用时仍会出现循环引用
1 2 3 4 @JsonIdentityInfo( generator = ObjectIdGenerators.PropertyGenerator.class, property = "id") public class CardModifyLog
5.其他方案
创建DTO,类似的思路还有创建接口投影或者实体视图,见Spring Data JPA和命名实体图 、Spring data jpa 投影 。 问题在于需要根据情况创建多个视图或者多个投影(DTO),由于各个实体间关系的复杂程度,不建议用此方式
使用@Transient注解使所有的关系不被存储即不与数据库的字段对应,同时存在于实体中,每次使用时,自己手动查询set 也许是一种好办法,但是失去了关系的约束,可能得不偿失
缓存AOP拦截失效问题 一.问题出现原因 Spring只有在代理对象之间进行调用时,可以触发切面逻辑才可以使用事务,在同一个class中,方法B调用方法A,调用的是原对象的方法,而不通过代理对象就无法使用事务,如果方法B有事务只会使用方法B的事务,不会去管方法A的事务所以一个类中方法调用当前类的其他拥有事务的方法时这个被调用方法事务会失效
一个类中方法调用当前类的其他拥有事务的方法时这个被调用方法事务会失效。在默认的代理模式下,只有目标方法由外部调用,才能被 Spring 的事务拦截器拦截
同理使用spring cache模块的@Cacheable等注解 在同一个class中互相调用是无法走缓存的 因为这样无法访问到spring容器中的那个代理对象
因为Springboot的缓存机制是通过切面编程aop来实现,从fill方法中调用listByCategory即内部调用,aop是拦截不到的,自然不会走缓存
二.问题解决方案 可以使用 AspectJ 取代 Spring AOP 代理来解决,也可以使用工具类诱发aop
fill方法调用诱发工具类
1 2 3 4 5 6 7 8 9 10 public void fill (Category category) ProductService productService = SpringContextUtil.getBean(ProductService.class); List<Product> products = productService.listByCategory(category); productImageService.setFirstProdutImages(products); category.setProducts(products); }
SpringContextUtil工具类诱发aop
我们需要在代码中需要动态获取其它bean,我们可以通过实现ApplicationContextAware接口来实现
ApplicationContextAware可以对当前bean传入对应的Spring上下文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package com.how2java.tmall.util;import org.springframework.context.ApplicationContext;import org.springframework.context.ApplicationContextAware;import org.springframework.stereotype.Component;public class SpringContextUtil implements ApplicationContextAware private static ApplicationContext applicationContext; public void setApplicationContext (ApplicationContext applicationContext) throws BeansException { SpringContextUtil.applicationContext = applicationContext; } public static ApplicationContext getApplicationContext () return applicationContext; } public static Object getBean (String beanId) throws BeansException return applicationContext.getBean(beanId); } }
分页动态数组开发 一.简单分页方法 1.Service层实现简单分页方法 这里使用JPA提供的Pageable类型对列表进行分页
Pageable是从0开始计算页数的,所以这里需要pageNum - 1
1 2 3 4 5 6 public Page<Category> getpage (int pageNum, int pageLimit) Pageable pageable = new PageRequest(pageNum - 1 , pageLimit); return categoryDAO.findAll(pageable); }
2.Controller层调用分页方法 通过@RequestParam设置从前台get方法发来的page和size信息
1 2 3 4 5 6 7 8 @GetMapping("/catepage") public Page<Category> pageList (@RequestParam(value = "page", defaultValue = "1") int page , @RequestParam(value = "size", defaultValue = "5") int size) throws Exception { return categoryService.getpage(page, size); }
3.测试结果 访问请求链接:http://localhost:8080/shopping_system/catepage?page=2&size=5
二.分页动态数组组类 1.分页功能进阶封装 JPA提供的分页类可以返回分割后的列表内容和分类信息如总共数据数(totalElements),总共分割的页面(totalPages)与当前访问的页面(number) ,但是这些数据不能方便提供一个方便的接口让前端实现部分分页节点展示 和分页节点遍历
当前是第8页,前面要显示3个,后面要显示3个,总共7条分页点,Pageable默认就不提供了,即Pageable无法实现根据当前选择页调整接口返回的数据,而只能硬性分页
所以我们需要做了一个 PageNavigator, 首先对 Page 类进行了封装,然后在构造方法里提供了一个 navigatePages 参数作为区间分页节点数
在构造方法里,还调用了 calcNavigatepageNums, 就是用来计算这个数值,并返回到一个int 数组变量 navigatepageNums ,方便前端遍历展示,而这个数组的大小为navigatePages
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 public class PageNavigator <T > Page<T> pageFromJPA; int totalPages; int number; long totalElements; int size; int numberOfElements; List<T> contents; boolean first; boolean last; boolean isHasContent; boolean isHasPrevious; boolean isHasNext; int navigatePages; int [] navigatepageNums; public PageNavigator () } public PageNavigator (Page<T> pageFromJPA, int navigatePages) this .pageFromJPA = pageFromJPA; this .navigatePages = navigatePages; totalPages = pageFromJPA.getTotalPages(); number = pageFromJPA.getNumber(); totalElements = pageFromJPA.getTotalElements(); size = pageFromJPA.getNumberOfElements(); contents = pageFromJPA.getContent(); isHasContent = pageFromJPA.hasContent(); first = pageFromJPA.isFirst(); last = pageFromJPA.isLast(); isHasNext = pageFromJPA.hasNext(); isHasPrevious = pageFromJPA.hasPrevious(); } private void calcNavigatepageNums () int [] navigatepageNums; int totalPages = getTotalPages(); int num = getNumber(); if (totalPages <= navigatePages){ navigatepageNums = new int [totalPages]; for (int i = 0 ; i < totalPages; i++){ navigatepageNums[i] = i + 1 ; } } else { navigatepageNums = new int [ navigatePages]; int startNum = num - navigatePages / 2 ; int endNum = 0 ; if (navigatePages % 2 == 0 ){ endNum = num + navigatePages / 2 - 1 ; } else { endNum = num + navigatePages / 2 ; } if (startNum < 0 ){ startNum = 1 ; for (int i = 0 ; i < navigatePages; i++){ navigatepageNums[i] = startNum++; } } else if (startNum > navigatePages){ endNum = totalPages; for (int i = navigatePages - 1 ; i >= 0 ; i--){ navigatepageNums[i] = endNum--; } } else { for (int i = 0 ; i < navigatePages; i++){ navigatepageNums[i] = startNum++; } } } this .navigatepageNums = navigatepageNums; } public int getTotalPages () return totalPages; } public void setTotalPages (int totalPages) this .totalPages = totalPages; } public int getNumber () return number; } public void setNumber (int number) this .number = number; } public long getTotalElements () return totalElements; } public void setTotalElements (long totalElements) this .totalElements = totalElements; } public int getSize () return size; } public void setSize (int size) this .size = size; } public int getNumberOfElements () return numberOfElements; } public void setNumberOfElements (int numberOfElements) this .numberOfElements = numberOfElements; } public List<T> getContents () return contents; } public void setContents (List<T> contents) this .contents = contents; } public boolean isFirst () return first; } public void setFirst (boolean first) this .first = first; } public boolean isLast () return last; } public void setLast (boolean last) this .last = last; } public boolean isHasContent () return isHasContent; } public void setHasContent (boolean hasContent) isHasContent = hasContent; } public boolean isHasPrevious () return isHasPrevious; } public void setHasPrevious (boolean hasPrevious) isHasPrevious = hasPrevious; } public boolean isHasNext () return isHasNext; } public void setHasNext (boolean hasNext) isHasNext = hasNext; } public int getNavigatePages () return navigatePages; } public void setNavigatePages (int navigatePages) this .navigatePages = navigatePages; } public int [] getNavigatepageNums() { return navigatepageNums; } public void setNavigatepageNums (int [] navigatepageNums) this .navigatepageNums = navigatepageNums; } }
除了上面的写法外,如果不需要修改方法名,完全可以在继承Page类的基础上进行拓展
2.Service层实现进阶分页方法 1 2 3 4 5 6 7 8 9 public PageNavigator<Category> getpage (int page, int size, int navigatePages) Sort sort = new Sort(Sort.Direction.DESC, "id" ); Pageable pageable = new PageRequest(page, size, sort); Page pageFrom = categoryDAO.findAll(pageable); return new PageNavigator<>(pageFrom, navigatePages); }
3.Controller层调用进阶分页方法 1 2 3 4 5 6 7 8 9 10 11 @GetMapping("/catepage") public PageNavigator<Category> pageList (@RequestParam(value = "page", defaultValue = "1") int page, @RequestParam(value = "size", defaultValue = "5") int size) throws Exception { page = page < 1 ? 1 : page; PageNavigator<Category> list = categoryService.getpage(page - 1 , size, 5 ); return list; }
4.测试结果 访问地址:http://localhost:8080/tmall_springboot/categories?start=3&size=2
可以看到最终实现了提供一个存储5个页面索引的数组
三.分页方法比较 JPA提供的分页类——Page可以满足各种分页需求,大部分时候用它就足够了,但是Pageable无法实现根据当前选择页调整接口返回的数据,而只能硬性分页即 页数(totalPage) = 数据数(totalElements) / 页大小(size)
表现在前端所有的分页都在一组分页栏中,如果想部分显示分页栏就需要前端去定制分页分组方法
但是如果前端有需求让后端根据当前选择页,以当前页为中点返回n个页面为一组的索引供前端调用
这时候我们就要对Page类进行封装,构造一个分页组类,在构造方法中提供一个navigatePages参数(分页组大小),并提供calNavigateNums方法根据当前页计算出分到同一组的页面索引并存储到数组navigatepageNums中供前端遍历展示
表现在前端可以通过接口获得当前页同一组分页的索引方便遍历
参考资料 Spring Data Elasticsearch基本使用
史上最全面的Elasticsearch使用指南
Spring data jpa中实体关系解决方案
Spring Data JPA 使用详解
Redis实用指南
延迟加载介绍