常用集合解析 必看资料:
渐进式本地缓存开发总结
Java集合面试题
Java集合源码分析
Java 编译期与运行期
JVM调试与栈溢出 必看资料:
循环依赖的解决方案
JDK 监控和故障处理工具总结
JVM 堆溢出抽丝剥茧定位的过程
JVM源码分析之栈溢出完全解读
JVM核心知识
一.栈溢出应用场景:循环依赖 在Springboot + JPA的架构中,容易出现循环依赖问题,一般会出现在一对多的场景下,总结来说是一对多实体中都要引用对方来维持OnetoMany的关系,所以极容易出现循环依赖:(
1.经典场景 订单项中引用订单,以构成多对一关系(可以使用订单id查到订单项)
1 2 3 4 @ManyToOne @JoinColumn(name="oid") private Order order;
订单中引用订单项存储在集合中,用来存储从数据库查询来的结构(往往是因为要利用这些字段进行计算)
1 2 3 4 5 6 7 8 9 @Transient private List<OrderItem> orderItems;@Transient private float total;@Transient private int totalNumber;
这样的结构就是循环依赖,导致数据重复加载,因为orderItems要调用方法填充,所以会为空(一般情况下会栈溢出)最终造成的数据是:Order含有orderItems,orderItems含有Order,Order的orderItem列表为空,所以这里的Order重复了一次
2.方案一:@JsonBackReference注解 JsonBackReference注解用在一(一对多的一)的一方,可以阻止其被序列化,前提是对应的接口不需要调用到它,而只是需要用它来查询
如:一个产品有多张图片,我们不需要在图片列表接口使用到产品信息,而只是需要用产品id查询其图片
产品类
1 2 3 4 5 6 7 @Transient private ProductImage firstProductImage;@Transient private List<ProductImage> productSingleImages;@Transient private List<ProductImage> productDetailImages;
产品图片类
1 2 3 4 @ManyToOne @JoinColumn(name="pid") @JsonBackReference private Product product;
缺点
关系是双向的,使用了JsonBackReference,就无法使用根据图片找到其属于的产品的方法,只能单方向查询即根据产品查找到其图片列表
JsonBackReference标记的字段与Redis的整合会有冲突
3.方案二:及时清除法 在服务层定义清除方法,在控制层调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void removeOrderFromOrderItem (List <Order> orders) for (Order order : orders) { removeOrderFromOrderItem(order); } } public void removeOrderFromOrderItem (Order order) List<OrderItem> orderItems= order.getOrderItems(); for (OrderItem orderItem : orderItems) { orderItem.setOrder(null ); } }
1 2 3 4 orderItemService.fill(page.getContent()); orderService.removeOrderFromOrderItem(page.getContent());
二.JVM 参考资料:JVM核心知识
多线程解析 必看资料:
Java多线程核心知识
多线程应用场景
Spring多线程批量发送邮件
Spring AOP解析 必看资料:
Spring @Cacheable注解类内部调用失效的解决方案
Spring AOP应用
AOP面试题
一.缓存AOP拦截失效问题 Spring @Cacheable注解类内部调用失效的解决方案
1.问题出现原因 因为Springboot的缓存机制是通过切面编程aop来实现,从fill方法中调用listByCategory即内部调用,aop是拦截不到的,自然不会走缓存,这里我们可以通过SpringContextUtil工具类诱发aop
1 2 3 4 5 6 7 8 9 10 public void fill (Category category) ProductService productService = SpringContextUtil.getBean(ProductService.class); List<Product> products = productService.listByCategory(category); productImageService.setFirstProdutImages(products); category.setProducts(products); }
2.问题解决方案 SpringContextUtil工具类诱发aop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.how2java.tmall.util;import org.springframework.context.ApplicationContext;import org.springframework.context.ApplicationContextAware;import org.springframework.stereotype.Component;@Component public class SpringContextUtil implements ApplicationContextAware private SpringContextUtil () } private static ApplicationContext applicationContext; @Override public void setApplicationContext (ApplicationContext applicationContext) SpringContextUtil.applicationContext = applicationContext; } public static <T> T getBean (Class<T> clazz) { return applicationContext.getBean(clazz); } }
二.AOP与日志处理 Spring AOP应用
三.SpringBoot原理 1.SpringBoot自动配置过程
2.SpringBoot启动过程
MySQL解析 必看资料 :
MySQL常见面试题总结
谈谈 MySQL 的 JSON 数据类型
简单总结 mysql json类型的利与弊
MySQL索引详解
数据库索引为什么使用B+树
一.物资申请系统数据库信息 MySQL常见面试题总结
1.物资申请表
用户id : 物资申请条目 = 1 : n
机构id : 物资申请条目 = 1 : n
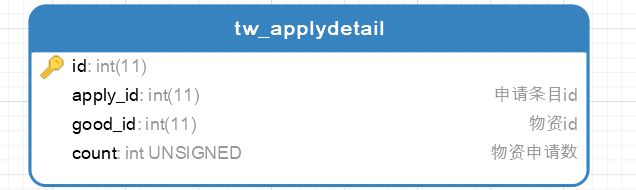
2.物资申请详情表
物资申请条目id : 物资申请详情条目 = n : n
物资id : 物资申请详情条目 = n : n
(物资申请条目id,物资id) : 物资申请详情条目 = 1 : n
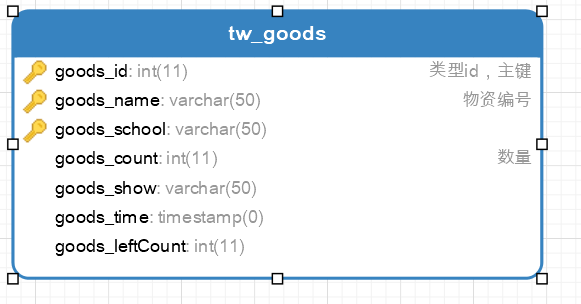
3.物资表
4.用户表
5.权限表
二.数据库分表 谈谈 MySQL 的 JSON 数据类型
简单总结 mysql json类型的利与弊
1.相关表的结构 此处展示的表结构为维护前
物资申请表:共4817条数据
物资信息表:
goods_count:当前仓库物品数(物理的)
good_leftCount:当前物品可借数(网络的:存在部分未借出,但已被预订仍在审核中的物品)
2.优化思路:物资申请表分表 改版前的系统使用的数据库是5.4版本,其默认的引擎是MyISAM 引擎,为了让数据库有更好的性能,我们将系统的数据库升级到了5.7.26版本,InnoDB 是 气的默认存储引擎
从上面的tw_apply表就可以知道:
由于Mysql对JSON类型的支持是5.7以后的版本才有的,所以之前版本的物品申请内容字符串是以物品 + 申请数量并用逗号隔开多个物品申请内容这样的格式构成,我一开始也考虑其转换为JSON格式,但是在考虑到应用场景后,决定对其进行分表,将多对多关系分为了两个一对多关系
数据库设计十分不合理,甚至不符合第一范式,浪费数据库大量存储空间 不说,而且后端拼接字符串解析字符串这一过程十分耗时且占用内存 ,而且最新的需求是需要增加一个审核过程申请物资调整功能
所以我将物资申请表进行分表(水平分表),分出物资申请详情表并联系物资信息表,其结构如下
删除掉apply_content字段,节省数据库空间
分表后,通过tw_applydetail表,我们对物资申请信息的所以内容进行操作,省去了物资审核接口对字符串解析的耗时过程并且方便审核过程申请物资调整功能的开发(通过tw_appdetail找到物品信息和物品数量)
3.优化操作:存储过程脚本 存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象
这里值得注意的是在遍历游标的循环中,如果查询不存在或为空会跳出循环
当时经过一天的对存储过程的学习,我总结出了以下经验:存储过程非常不方便调试,而且报错信息只定位不报错误类型(sql是这样的)。如果能重来,对数据库的批量操作,首选Python或Shell
4.优化结果
截至目前物资申请表已有4817条数据,考虑到后面数据会长期积累,这样的优化是有必要的
去掉后端耗时耗内存的字符串解析工作
节省数据库存储空间,优化前申请表内存占0.79MB,优化后占0.56MB
另外附加一个容量查询小工具,可查询数据库各表容量大小
1 2 3 4 5 6 7 8 9 select table_schema as '数据库', table_name as '表名', table_rows as '记录数', truncate(data_length/1024/1024, 2) as '数据容量(MB)', truncate(index_length/1024/1024, 2) as '索引容量(MB)' from information_schema.tables where table_schema='bgs' order by data_length desc, index_length desc;
三.数据库索引的使用 MySQL索引详解
数据库索引为什么使用B+树
由于日志表数据庞大,有3万条数据,为了达到快速通过用户名模糊查找到日志操作内容和操作时间,我一开始的方案是选择了使用索引,以操作人作为索引模糊查询操作日志
1.相关表结构 日志记录表:共33687条数据
2.优化思路:添加索引 另外在模糊查询中,like语句要使索引生效,like后不能以%开始,也就是说 (like %字段名%) 、(like %字段名)这类语句会使索引失效,而(like 字段名)、(like 字段名%)这类语句索引是可以正常使用
所以我将查询的模糊匹配由“%xxxx%”改为“xxxx%”,只模糊匹配前面部分
3.优化操作 这里直接使用Navicat可视化添加索引,因为后台查询日志是需要用用户名模糊查找到日志操作内容和操作时间,所以需要添加的索引为log_realnam
更改mybatis的sql映射,解决sql注入和索引失效问题
1 SELECT log_realname, log_content, log_time FROM tw_log WHERE log_realname LIKE "%${log_name}%";
在这种情况下使用#程序会报错,新手程序员就把#号改成了$,这样如果java代码层面没有对用户输入的内容做处理势必会产生SQL注入漏洞。
正确写法:
1 SELECT log_realname, log_content, log_time FROM tw_log WHERE log_realname LIKE concat(‘%’,#{log_name}, ‘%’)
4.优化结果
添加索引前使用用户名模糊查询日志,耗时大约0.045s,添加索引后耗时大约0.032s,减少了磁盘IO,提高了查询速度
修改mybatis中模糊查询的sql语句,解决索引失效的问题,并解决了模糊查询中拼接字符串的sql注入问题
但是加索引这种方案没有被采纳,因为在系统上操作日志包括了,注册登录申请审批等操作,插入是非常频繁的,而日志查询只会被管理员少量使用,所以后续使用了ES来提高查询效率
大数据框架解析 必看资料:
Spring Data Elasticsearch基本使用
史上最全面的Elasticsearch使用指南
一.ES搜索操作日志 史上最全面的Elasticsearch使用指南
1.ES准备 ES是什么
elasticsearch简写es,es是一个高扩展、开源的全文检索和分析引擎,它可以准实时地快速存储、搜索、分析海量的数据,而这正好符合我们的需求,物资申请系统的操作日志刚好是一个存储频繁,又需要对大量数据进行查询统计的场景
什么是全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索搜索引擎数据库中的数据。
配置ES
1 2 spring.data.elasticsearch.cluster-nodes = 127.0.0.1:9300
ES注解实体类
1 2 3 @Document(indexName = "tmall_springboot",type = "product")
2.esDAO的创建 由于整合了ES的JPA和操作数据库使用的JPA有冲突,所以不能放在同一个包下
1 2 3 4 5 6 7 8 9 10 11 12 package com.how2java.tmall.es;import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;import com.how2java.tmall.pojo.Product;public interface ProductESDAO extends ElasticsearchRepository <Product ,Integer >}
3.ES与数据库同步 增删改操作
增删改操作的数据需要同步ES和数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @CacheEvict(allEntries=true) public void add (Product bean) productDAO.save(bean); productESDAO.save(bean); } @CacheEvict(allEntries=true) public void delete (int id) productDAO.delete(id); productESDAO.delete(id); } @CacheEvict(allEntries=true) public void update (Product bean) productDAO.save(bean); productESDAO.save(bean); }
ES初始化
ES内数据为空,就将数据库中的数据同步到es
1 2 3 4 5 6 7 8 9 10 11 12 13 private void initDatabase2ES () Pageable pageable = new PageRequest(0 , 5 ); Page<Product> page =productESDAO.findAll(pageable); if (page.getContent().isEmpty()) { List<Product> products= productDAO.findAll(); for (Product product : products) { productESDAO.save(product); } } }
4.ES查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public List<Product> search (String keyword, int start, int size) initDatabase2ES(); FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery() .add(QueryBuilders.matchPhraseQuery("name" , keyword), ScoreFunctionBuilders.weightFactorFunction(100 )) .scoreMode("sum" ) .setMinScore(10 ); Sort sort = new Sort(Sort.Direction.DESC,"id" ); Pageable pageable = new PageRequest(start, size,sort); SearchQuery searchQuery = new NativeSearchQueryBuilder() .withPageable(pageable) .withQuery(functionScoreQueryBuilder).build(); Page<Product> page = productESDAO.search(searchQuery); return page.getContent(); }
Redis解析 必看资料:
缓存基础常见面试题总结
Redis常见面试题总结
渐进式本地缓存开发总结
缓存一致性问题解决基本方案
缓存一致性问题解决进阶方案
一.Redis需求分析 我们为了避免用户在请求数据的时候获取速度过于缓慢,同时也为了承受大量的并发请求,所以我们在数据库之上增加了缓存这一层来弥补 ,本系统主要使用的是Redis,将常用的数据存储在缓存中(如物品,用户信息等)
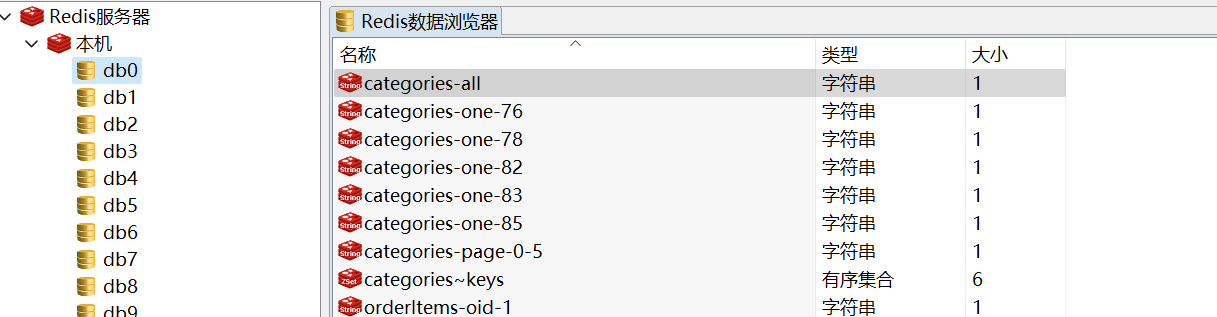
另外推荐使用RedisClient,数据一般都在db0中
二.Redis配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 spring.redis.database =0 spring.redis.host =127.0.0.1 spring.redis.port =6379 spring.redis.password =spring.redis.pool.max-active =10 spring.redis.pool.max-wait =-1 spring.redis.pool.max-idle =8 spring.redis.pool.min-idle =0 spring.redis.timeout =0
三.缓存的使用 缓存的使用一般在服务层使用
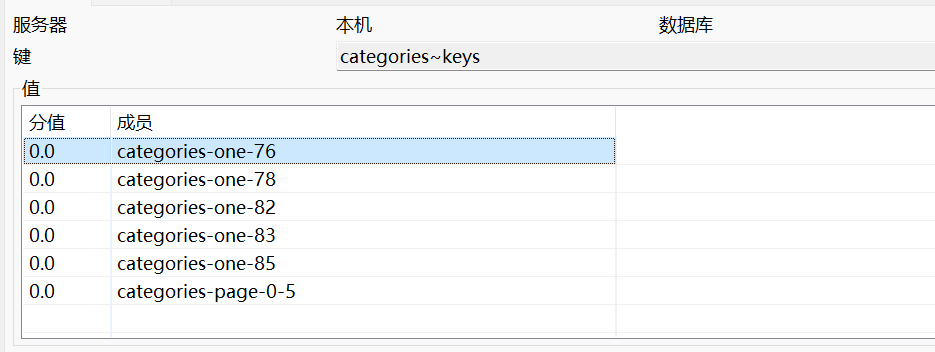
1.有序集合管理 通过在服务层中注解@CacheConfig,创建一个有序集合类型的缓存,管理该服务下所有的keys
1 2 3 4 5 6 7 8 @Service @CacheConfig(cacheNames="categories") public class CategoryService ..... }
2查询插入缓存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Cacheable(key="'categories-one-'+ #p0") public Category get (int id) Category c= categoryDAO.findOne(id); return c; } @Cacheable(key="'categories-page-'+#p0+ '-' + #p1") public Page4Navigator<Category> list (int start, int size, int navigatePages) Sort sort = new Sort(Sort.Direction.DESC, "id" ); Pageable pageable = new PageRequest(start, size, sort); Page pageFromJPA =categoryDAO.findAll(pageable); return new Page4Navigator<>(pageFromJPA,navigatePages); }
返回的java对象或集合都会变成JSON字符串
3.更新删除缓存 为了应对并发的申请请求提高,我们在Mysql数据库前加了一层Redis,所以在我开发后台物资储存量调整接口时遇到了缓存和数据库中物品数量不一致的问题
准确来说是插入,删除,更新删除缓存以保持数据一致性
使用@CacheEvict(allEntries=true)删除category~keys的所有keys
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @CacheEvict(allEntries=true) public void add (Category bean) categoryDAO.save(bean); } @CacheEvict(allEntries=true) public void delete (int id) categoryDAO.delete(id); } @CacheEvict(allEntries=true) public void update (Category bean) categoryDAO.save(bean); }
四.缓存一致问题解决 基本:缓存一致性问题解决基本方案
进阶:缓存一致性问题解决进阶方案
分布式微服务解析 参考资料:
RPC与Dubbo
SpringCloud Alibaba 及其组件
消息队列
SpringCloud Alibaba详解
高并发高可用解析 高可用系统设计指南
限流相关算法
系统设计与性能测试解析 系统设计