
MySQL ❎
OurSQL ✅
Debain安装MySQL
添加 MySQL 存储库
MySQL 服务器包可通过其官方存储库获得。 因此,我们现在将下载并安装 MySQL 存储库安装包
1 | wget https://dev.mysql.com/get/mysql-apt-config_0.8.18-1_all.deb |
使用 dpkg
1 | sudo dpkg -i mysql-apt-config_0.8.18-1_all.deb |
进入mysql安装页面选择ok即可
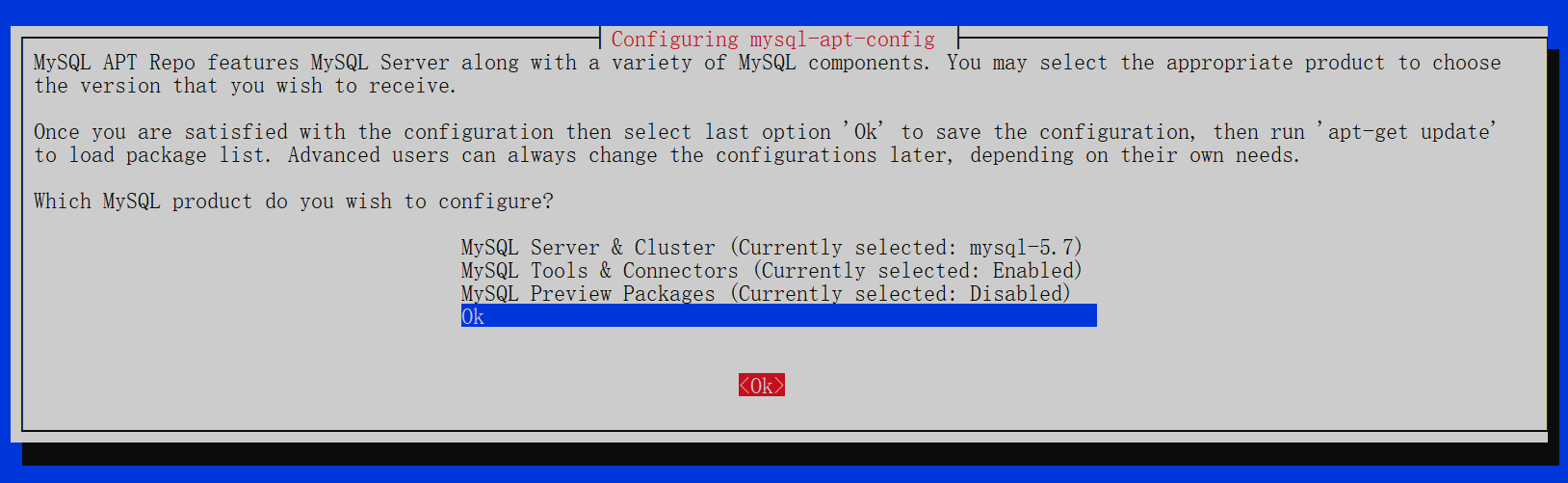
安装mysql
等待存储库配置完成,然后使用 apt 命令更新存储库索引
1 | sudo apt update |
安装mysql服务器
使用apt-get install mysql-server安装时,如果出现报错Package ‘mysql-server’ has no installation candidate,可以使用下面的命令进行安装
1 | sudo apt-get install mariadb-server |
启动服务
理论上这时候的mysql服务已经安装完成了,我们可以通过命令service –status-all 查看到服务列表中有mariadb
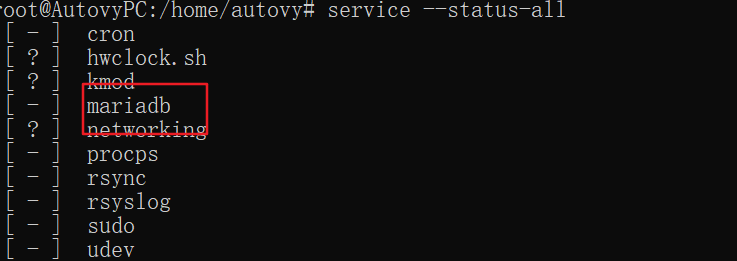
但是使用mysql命令时,会出现以下报错,这是因为mariadb服务还未启动

使用以下命令启动即可
1 | service mariadb start |

命令行准备数据库
root账号进入数据库
mysql命令进入mysql服务
1 | mysql |
修改root账号密码

1 | set password for root@localhost = password("123456") |
退出mysql服务,并使用root账号登录
1 | exit |
1 | mysql -u root -p |

新用户与新数据库
创建新数据库
1 | create database testdb; |
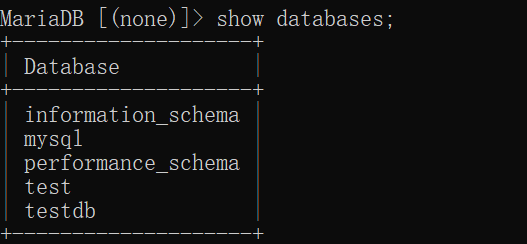
查看已有数据库
1 | show databases; |
创建新用户
@localhost设置只允许用户本地登录,并设置其密码为123456
1 | create user aut@localhost identifide by '123456'; |

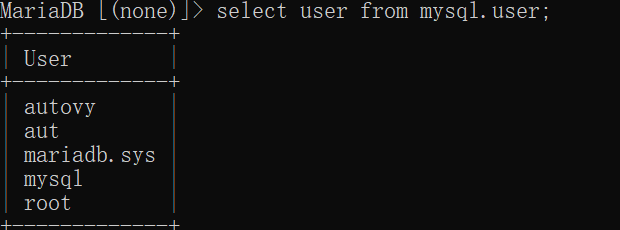
查看用户列表
1 | select user for mysql.user |
分配新数据库给新用户
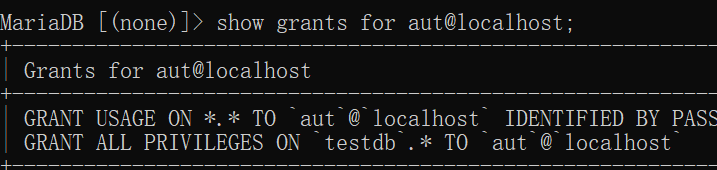
注意这里是指将testdb库的所有表(testdb.*)的所有权限(all)给aut本地使用(localhost)
1 | grant all on testdb.* to aut@localhost; |

查看用户权限
1 | show grants for aut@localhost; |
测试数据准备
使用新用户aut连接mysql
1 | mysql -u aut -p |
切换数据库到新数据库
1 | use testdb; |
创建一个只含一个字段的数据表
test表只含有一个整型不为空的字段money
1 | create table test (money int not null) |
添加一条数据到表中
1 | insert test(money) values(5000) |
MySQL事务隔离实验
新开一个终端使用连接上新数据库testdb(可以aut,也可以自己新建一个用户)
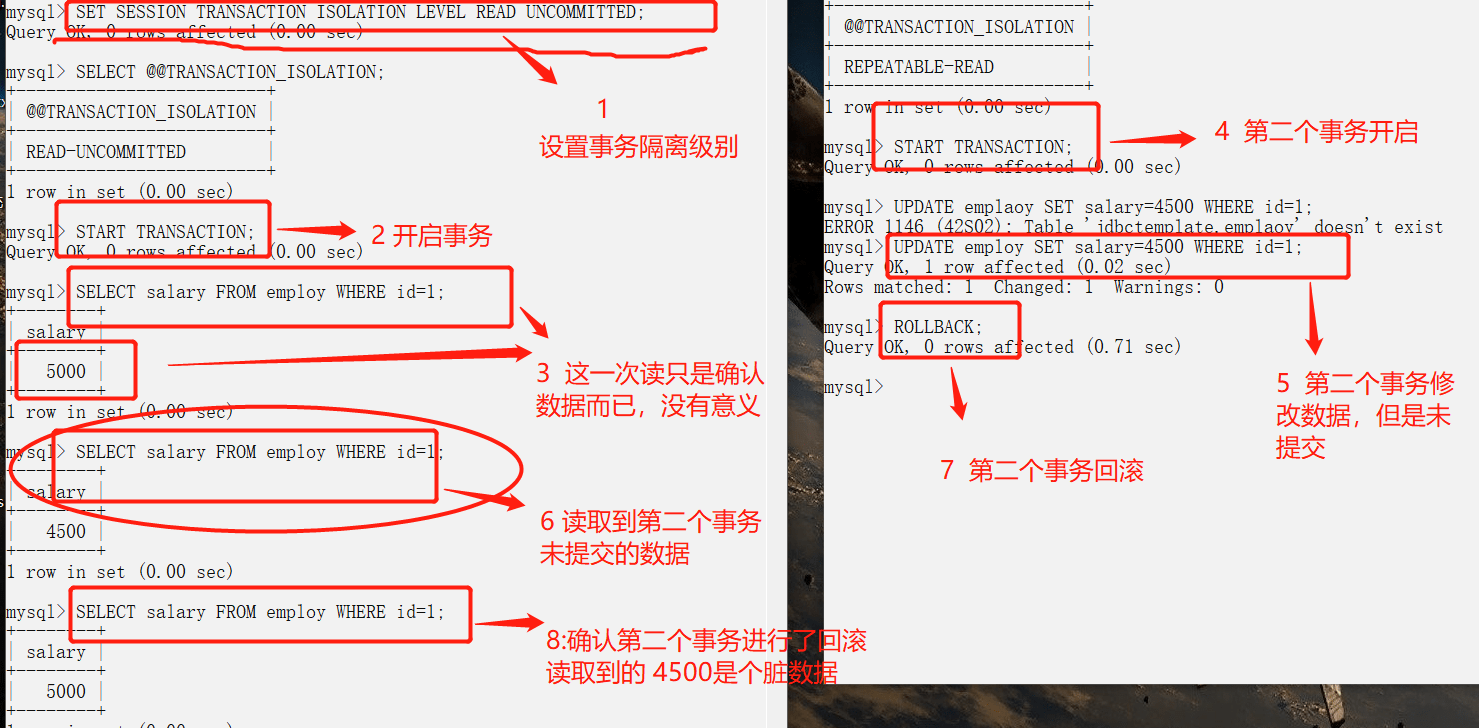
读未提交级别
出现脏读问题
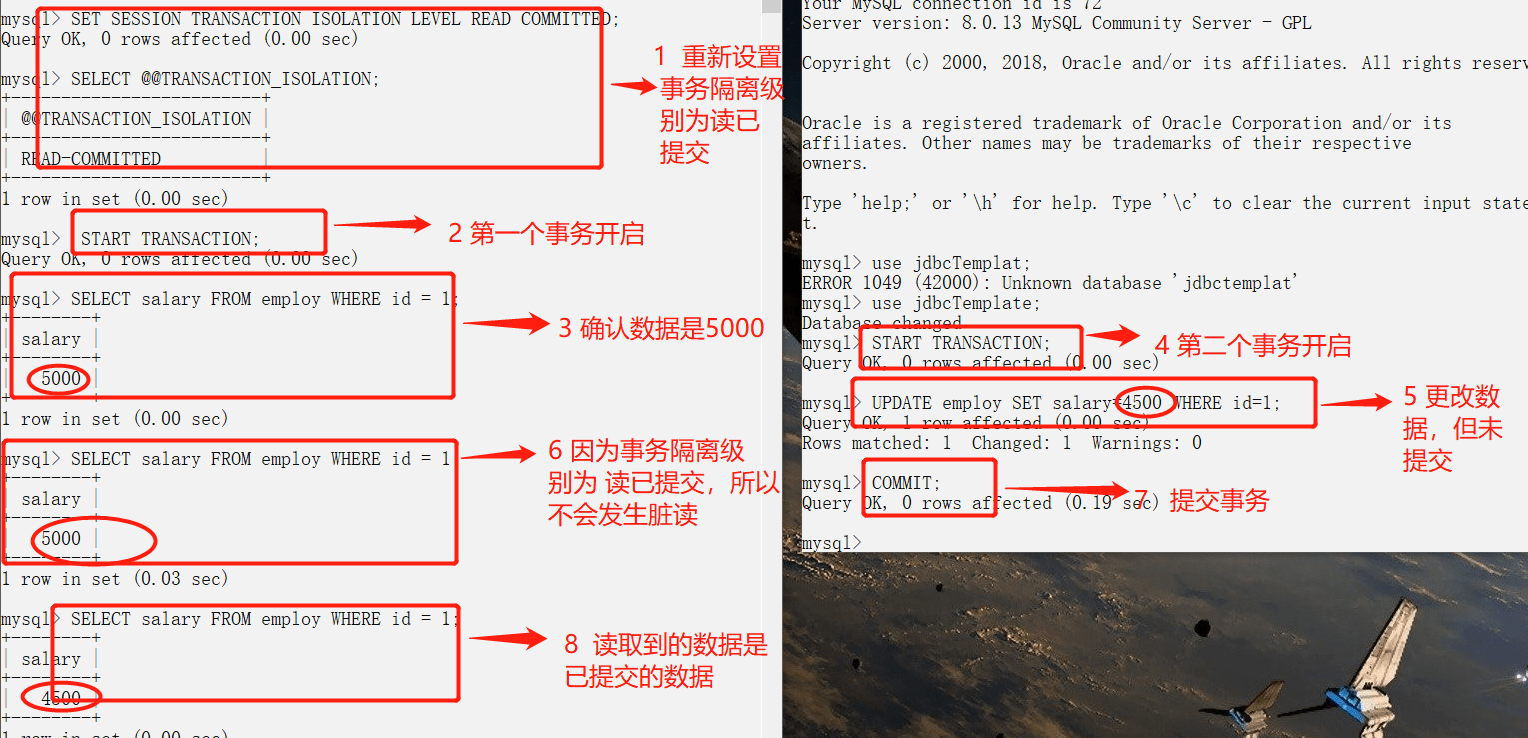
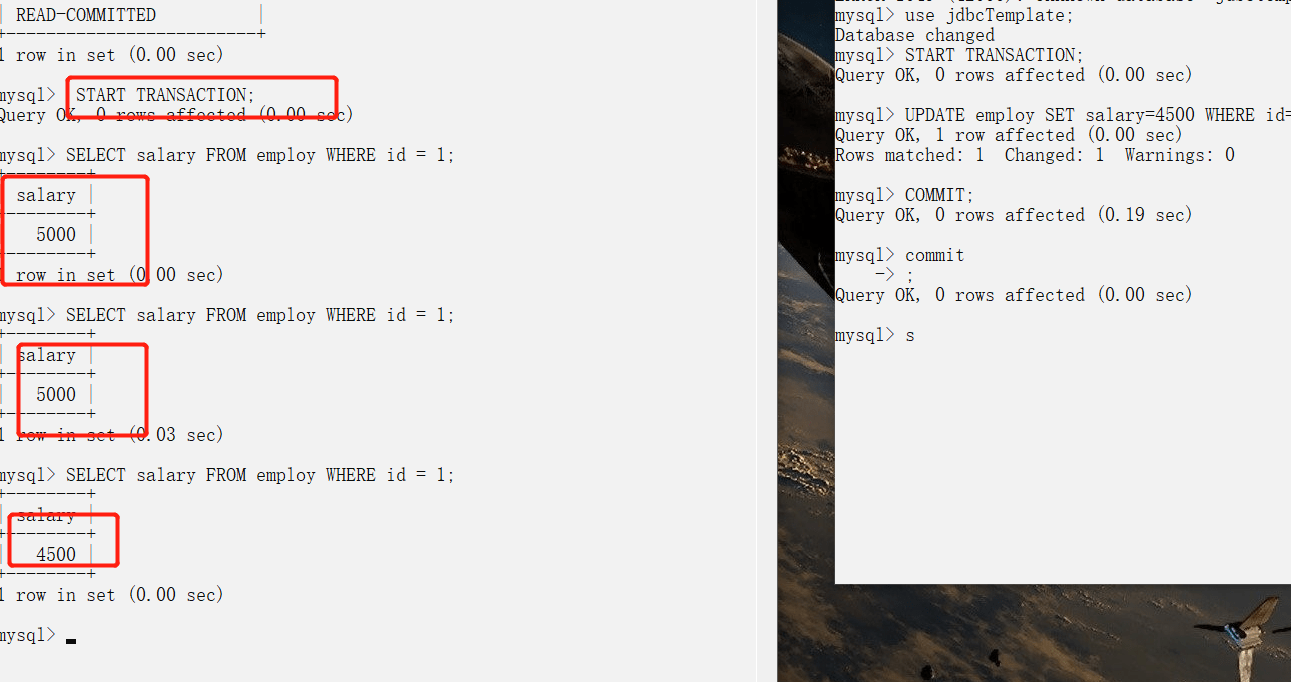
读已提交级别
避免脏读,但是不可重复读
1.避免脏读测试
2.不可重复读测试
可重复读级别
可以重复读,并且可以防止幻读
1.可重复读测试
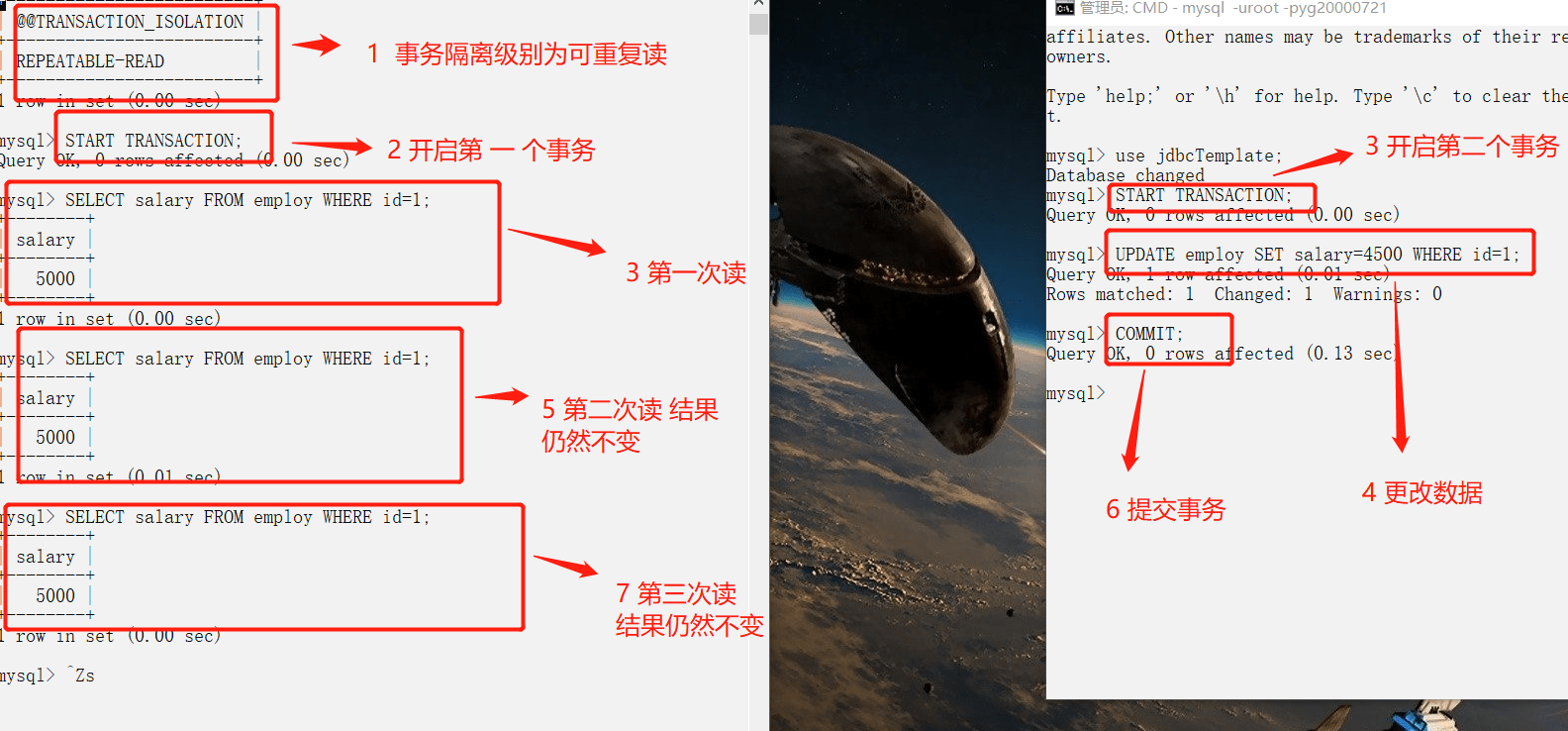
2.防止幻读测试
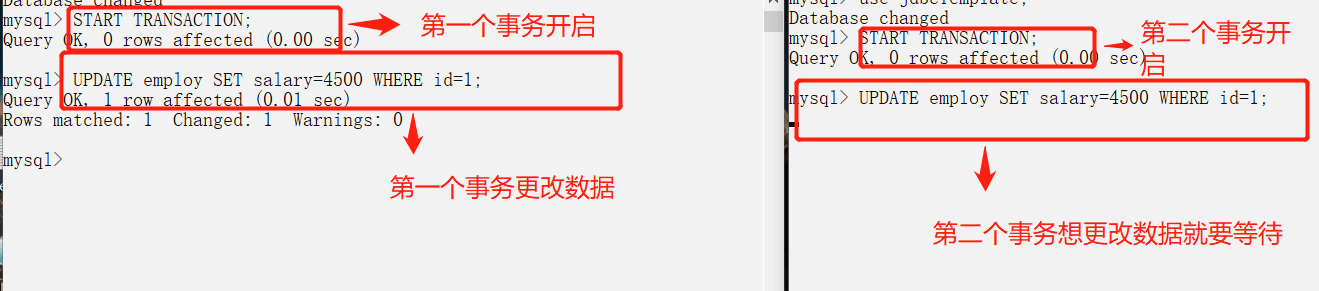
MySQL优化实验
上面的实验全程在Linux环境中,在日常开发中我们可以使用数据库可视化工具如Navicat或IDEA自带的数据库工具,下面我主要使用Navicat进行操作
此章节的优化实例来自一次对学校校团委物资管理系统的维护,鉴于此项目糟心的数据库设计,给我留下了深刻的印象,难以想象的是这样的项目竟然从16年运行至今
T-SQL脚本分表优化
1.相关表的结构
此处展示的表结构为维护前
物资申请表:共4817条数据

物资信息表:
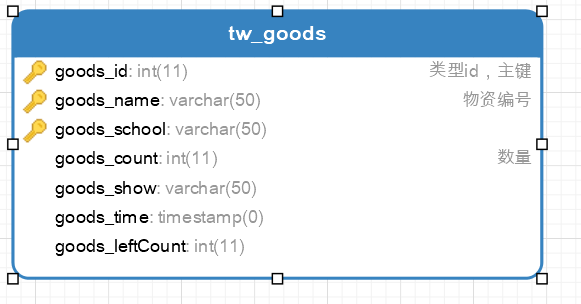
goods_count:当前仓库物品数(物理的)
good_leftCount:当前物品可借数(网络的:存在部分未借出,但已被预订仍在审核中的物品)
2.优化思路:物资申请表分表
从上面的tw_apply表就可以知道:
在用户提出申请后,物资申请信息被后端拼成了一个字符串存储在apply_content(同时利用了前端的数据执行了物品可借数的预扣除,所以这部分没有用到物资申请信息字符串的解析)
通过审核后,物品正式借出,这时候只留有物资申请信息的字符串存储在数据库,所以需要后端对该字符串解析提取出申请物资与其借用数量,再去操作数据库
还好后端大哥没有把物资申请信息的字符串直接发给前端,我真的哭死,设计数据库的那个出来挨打(前端不需要解析,但是要拼接展示字符串)
数据库设计十分不合理,甚至不符合第一范式,浪费数据库大量存储空间不说,而且后端拼接字符串解析字符串这一过程十分耗时且占用内存,而且最新的需求是需要增加一个审核过程申请物资调整功能
所以我将物资申请表进行分表(水平分表),分出物资申请详情表并联系物资信息表,其结构如下
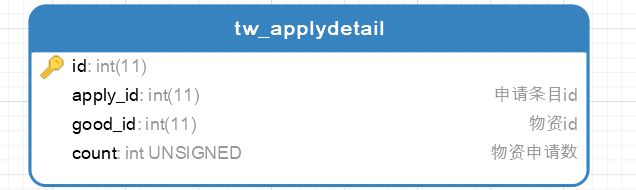
删除掉apply_content字段,节省数据库空间
分表后,通过tw_applydetail表,我们对物资申请信息的所以内容进行操作,省去了物资审核接口对字符串解析的耗时过程并且方便审核过程申请物资调整功能的开发(通过tw_appdetail找到物品信息和物品数量)
3.优化操作:存储过程脚本
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象
这里值得注意的是在遍历游标的循环中,如果查询不存在或为空会跳出循环
1 | CREATE DEFINER=`Autovy`@`localhost` PROCEDURE `demo`() |
当时经过一天的对存储过程的学习,我总结出了以下经验:存储过程非常不方便调试,而且报错信息只定位不报错误类型(sql是这样的)。如果能重来,对数据库的批量操作,首选Python或Shell
4.优化结果
- 截至目前物资申请表已有4817条数据,考虑到后面数据会长期积累,这样的优化是有必要的
- 去掉后端耗时耗内存的字符串解析工作
- 节省数据库存储空间,优化前申请表内存占0.79MB,优化后占0.56MB
另外附加一个容量查询小工具,可查询数据库各表容量大小
1 | select |
索引优化查询
1.相关表结构
日志记录表:共33687条数据

2.优化思路:添加索引
关于索引的知识点这里不细说,推荐阅读:MySQL 索引详解
由于日志表数据庞大,有3万条数据,为了达到快速通过用户名模糊查找到日志操作内容和操作时间,就需要用到索引,另外在模糊查询中,like语句要使索引生效,like后不能以%开始,也就是说 (like %字段名%) 、(like %字段名)这类语句会使索引失效,而(like 字段名)、(like 字段名%)这类语句索引是可以正常使用
所以我将查询的模糊匹配由“%xxxx%”改为“xxxx%”,只模糊匹配前面部分
3.优化操作
这里直接使用Navicat可视化添加索引,因为后台查询日志是需要用用户名模糊查找到日志操作内容和操作时间,所以需要添加的索引为log_realnam

更改mybatis的sql映射,解决sql注入和索引失效问题
1 | SELECT log_realname, log_content, log_time FROM tw_log WHERE log_realname LIKE "%${log_name}%"; |
在这种情况下使用#程序会报错,新手程序员就把#号改成了$,这样如果java代码层面没有对用户输入的内容做处理势必会产生SQL注入漏洞。
正确写法:
1 | SELECT log_realname, log_content, log_time FROM tw_log WHERE log_realname LIKE concat(‘%’,#{log_name}, ‘%’) |
4.优化结果
- 添加索引前使用用户名模糊查询日志,耗时大约0.045s,添加索引后耗时大约0.032s,减少了磁盘IO,提高了查询速度
- 修改mybatis中模糊查询的sql语句,解决索引失效的问题,并解决了模糊查询中拼接字符串的sql注入问题
参考资料
怎样在 Debian 11 / Debian 10 上安装 MySQL 8.0 / 5.7
install.packages - MySQL: Package ‘mysql-server’ has no installation candidate - Stack Overflow
/1190000039248897)